Intro
이번에 리뷰할 논문은 앞선 리뷰 visual retrieval 기반 localization인 ‘Leveraging deep visual descriptors for hierarchical efficient localization‘ 의 확장 연구입니다. 이전 리뷰에서는 learnable 부분이 NetVLAD가 토대인 global descriptor으로만 구성되어있다면, 이번 확장 연구에서는 global descriptor와 local descriptor를 learnable하도록 구성함으로써 localization의 성능을 향상시켰습니다.
Introduction
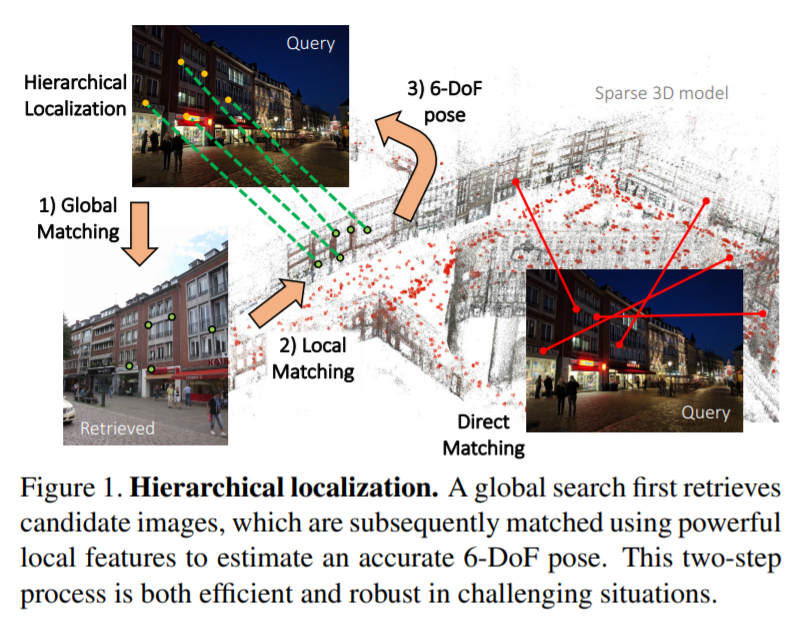
Hierarchical Feature Network(이하 HF-Net)은 사람이 시각적인 정보를 토대로 localization을 수행하는 방법과 유사합니다. 장소에 대한 기억을 통해 유사한 후보 장소를 기억하고 세부적으로 매칭을 시켜 localization을 수행합니다. 이를 HF-Net에 빗대어 설명하자면 현재 위치의 시각적인 정보 query를 이전의 기억 database를 토대로 유사한 장소(global descriptor간 knn 에서의 후보 영상(prior/top k))를 검색합니다. 검색된 영상들과 query를 세부적으로 관찰( local descriptor와 PnP를 이용한 pose estimation)하여 localization을 수행합니다.
위의 방법은 앞서 리뷰한 논문의 프레임과 유사한 방식입니다. 이전과 방법보다 개선된 점은 local과 global descriptor의 계산을 공유하면 학습이 가능하게 함으로써 보다 강인하고 효율성 있도록 한 것에 있습니다.
Hierarchical localization
앞서 설명한 것처럼 HF-Net은 이전 논문을 기반으로 합니다. 그렇기에 자세한 설명은 생략하며, 간략한 설명으로 대신하겠습니다.
- Prior retrieval
- 입력 받은 query와 사전 계산된 database를 global descriptor로 추론하여 kNN을 수행해 top k를 선정합니다.
- 이는 SfM의 point를 이용하는 방법보다 적은 계산량을 가지기 때문에 효율적입니다.
- Covisibility clustering
- 같은 장소를 관찰하는 top k간 군집시킵니다.
- Local feature mathcing
- query의 2D point와 top k에서 얻어진 3D point간 PnP RANSAC을 수행하여 6-DOF를 추정합니다.
- Learnable global descriptor
- NetVALD를 teacher, MobileNet + NetVLAD를 student로 하여 distillation을 수행한 MobileNetVALD(MNV)을 global descriptor로 이용합니다.
- Distillation을 수행한 MNV는 GPU/CPU에서 수행되는 hand-craft feature(e.g. SIFT)보다 계산량이 효율적이며 조도 변화가 큰 경우에서는 보다 나은 성능을 보여줬습니다. [참고 논문 작성]
HF-Net
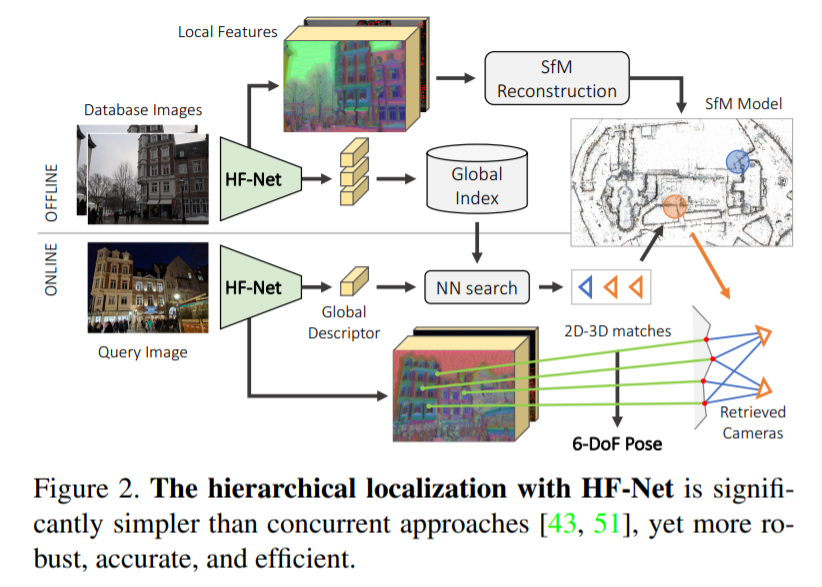
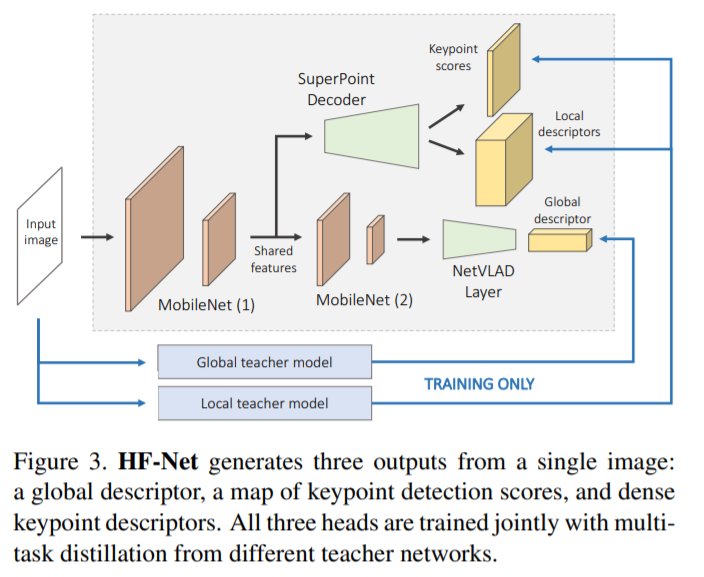
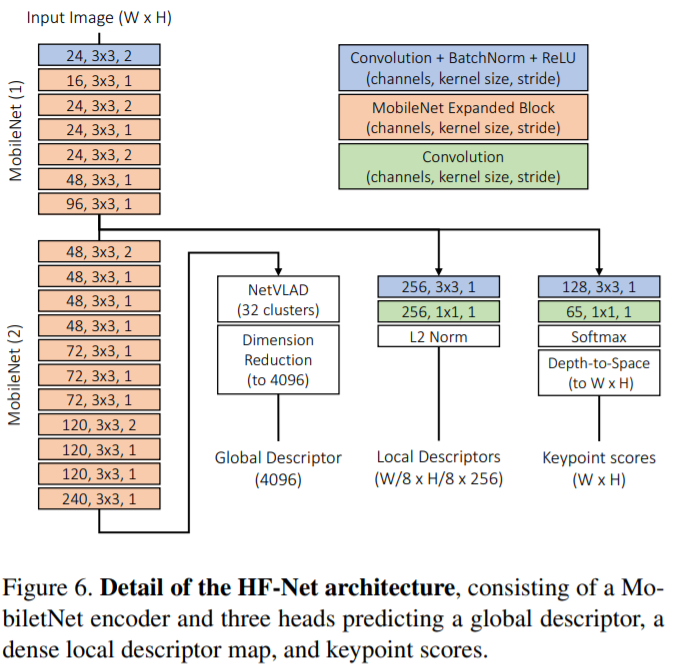
HF-Net은 Hierarchical localization 을 그대로 계승하되 learnable feature를 사용하였습니다. HF-Net의 구조는 fig 3.에서 확인 할 수 있으며, 전체적인 pipeline은 Fig 2. 통해 확인 할 수 있습니다. 구체적은 모델의 구조는 Fig 6.을 참고하시면 됩니다.
- HF-Net은 local과 global feature를 동시에 예측함으로써 계산의 효율성을 얻습니다. 예측하는 값은 세 가지가 있습니다.
- keypoint detection scores
- dense local descriptor
- global image-wide descriptor
- 기반이 되는 모델은 MNV이며, local feature인 경우, 공간적으로 구별되는 특징을 유지하기 위해 global descriptor보다 빠른 layer를 사용합니다.
- 또한 계산의 효율성과 구별력을 키우기 위해 local descriptor인 경우 learnable한 local feature인 SuperPoint를 이용합니다.
- MNV와 SuperPoint를 결합하여 공유된 자원으로 local, global feature 학습함으로써 계산 효율성과 성능 향상을 얻었습니다.
- HF-net으로 예측된 세 가지 값들은 수식 (1)를 통해 학습되어 집니다.
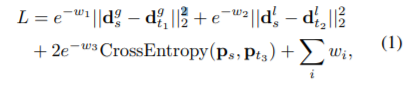
knowledge distillation
- 해당 논문의 독특한 특징은 학습을 SOTA를 달성한 모델들을 이용하여 knowledge distillation한 것에 있습니다.
- Global descriptor인 경우 NetVLAD, local feature는 SuperPoint를 이용하여 학습하였습니다.
- HF-Net이 knowledge distillation 을 이용하여 학습한 이유는 아래와 같습니다.
- NetVLAD인 경우, anchor를 pos, neg data간 거리가 멀어지게 하는 metric learning을 이용하여 학습합니다. 하지만 존재하는 대부분의 데이터셋들은 학습에 충분한 대응 데이터를 제공하지 못하고 있습니다. 예를 들어 day-night-seasons등 환경에 변화 / 정확하게 일치하는 매칭되는 대응 데이터 를 제공하는 데이터 수가 적기에 적용하기 힘든 점이 있습니다.
- SuperPoint는 대응 데이터에 필수로 요구되지 않는 Self-supervised를 이용하여 학습합니다. 하지만 대량의 data augmentation이 요구됩니다. 너무 많은 data augmentation은 global consistency를 깨뜨리게 되어 global descriptor의 학습을 고되게 만듭니다.
- 다른 이유로는 SOTA를 달성한 모델의 성능을 작은 모델에 적용하게 되어 빠른 runtime과 모델 크기에 비해 높은 성능을 가질 수 있다는 장점이 있습니다.
최종적으로 HF-Net은 MNV와 SuperPoint이 결합된 모델을 각각의 task에서 SOTA를 달성된 모델로 knowledge distillation으로 학습됩니다. HF-Net으로 추론된 local/global descriptor는 앞선 리뷰인 Hierarchical localization 방법으로 이어져 pose를 추론합니다.
Evaluation
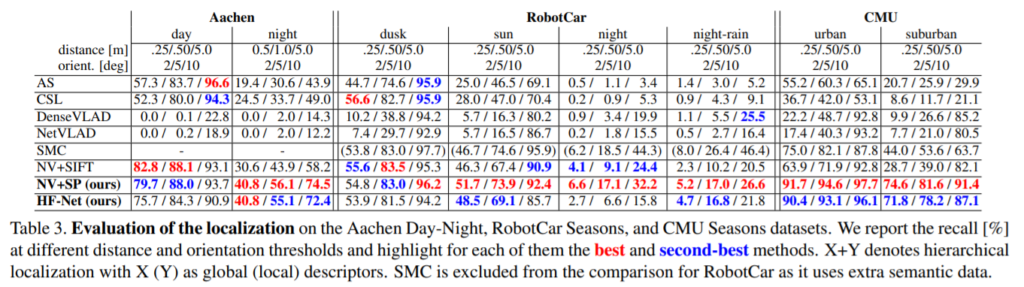
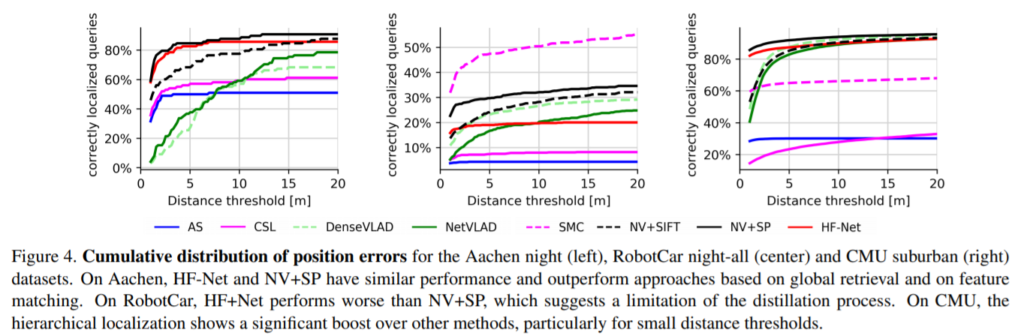
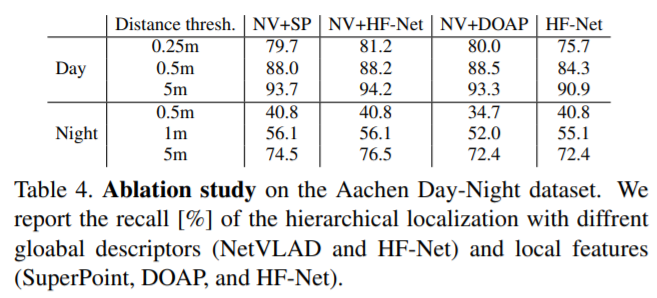
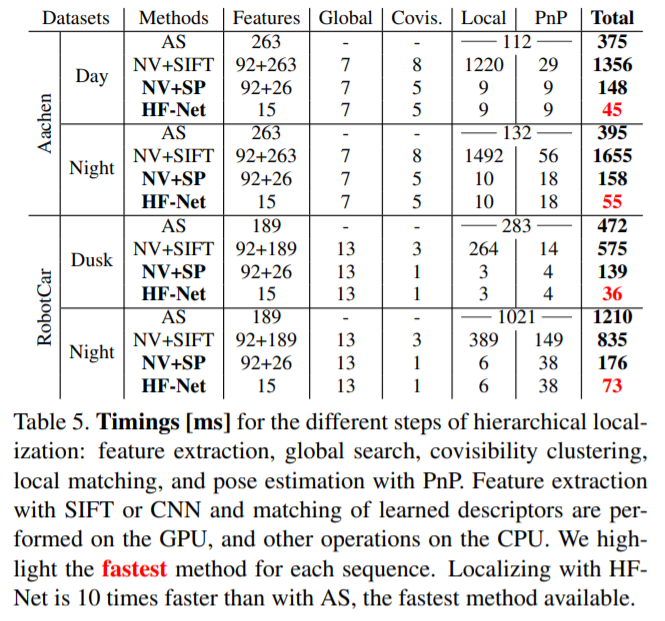
Aachen, RobotCar의 night, 상대적으로 어려운 CMU에서 가장 높은 성능을 보여주는 특징을 보여줍니다. 또한 최대 20fps(Table 5)로 추론하는 성능을 보여줍니다.