
논문: PointNet++: Deep Learning on Point Sets for 3D Classification and Segmentation
블로그 시리즈:
1. Review: PointNet
이번 논문은 지난 PointNet[1] 리뷰에 이어 같은 연구자 발표한 PointNet++ 논문입니다. PointNet의 문제점으로 지적된 local feature 요소가 없이 때문에 표현력이 떨어지는 점을 보완하기 위해 CNN의 방법에서 아이디어를 얻어 국소적인 특성부터 전체적인 특성까지 점차 시야를 넓혀가며 진행하는 계층적 방법을 사용했습니다. (PointNet++ 의 코드는 https://github.com/charlesq34/pointnet2 를 참고하세요.)
논문의 시작은 PointNet이 point clouds data를 직접 사용한 선구적인 연구였다는 이야기로 시작합니다. 그리고 2D 이미지 방법과 같이 local feature와 global feature를 뽑아 특징을 잘 서술하는 것이 아니라 point clouds 특징을 바로 붙여버리기 때문에 국소적인 부분을 표현하기에 부족한 점이 문제라고 지적하였습니다. 지적된 문제를 해결하기 위해 CNN이 convolution을 반복하면서 점차 넓은 차원으로 특징을 뽑아내는 점에 착안하여 point clouds data를 작은 단위로 나누고 작은 PointNet을 통과시켜 나오는 결과가 local feature로 정의한 후 이 과정을 반복하면 global feature도 뽑을 수 있다는 것이 핵심입니다.
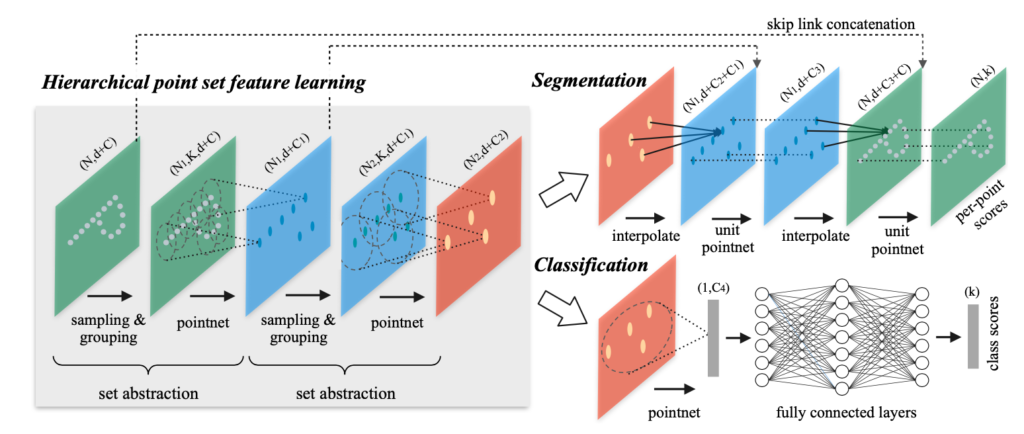
그림 1은 PointNet++의 구조이며 다시 한번 핵심 흐름을 말하자면:
1. Input data를 작은 그룹으로 묶고 각 그룹에 PointNet을 실행하여 local feature를 얻음
2. Local feature를 다시 그룹으로 묶고 다시 한번 PointNet을 실행하여 global feature를 얻음
3. Global feature를 이용하여 classification과 segmentation을 진행
이어서 그림 1에 나와 있는 set abstraction에 대해 간략히 설명하겠습니다.
Sampling layer에서는 farthest point sampling (FPS)를 사용하여 input data의 작은 그룹을 선택하게 됩니다. 여기서 사용한 FPS 방법에 대해서는 좀 더 이해를 한 후 내용을 공유해드리겠습니다. Grouping layer에서는 sampling된 data를 ball query 혹은 kNN으로 그룹(구현된 코드에서는 64개의 그룹으로 설정)으로 나누게 됩니다. 그리고, 각 그룹별로 PointNet layer를 통과시켜 local feature를 뽑고 위 과정을 한 번 더 반복하는 것으로 국소적인 지역의 특징에서 전체적인 특징을 볼 수 있도록 해줍니다.
위와 같은 set abstraction 과정이 끝난 후 classification과 segmentation은 그림 1과 같은 과정을 진행해줌으로써 결과를 얻을 수 있습니다.
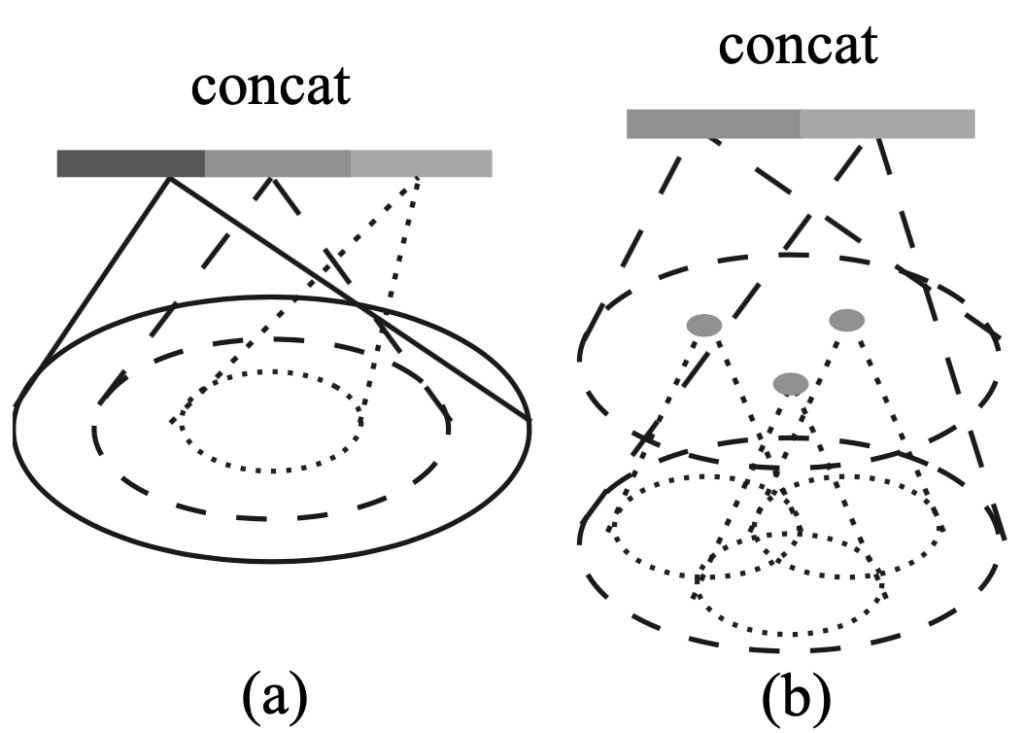
이 논문에서는 point clouds data에서 sampling을 할 경우 density가 불균형인 문제를 지적하고 있습니다. 제기된 문제를 해결하기 위해 그림 2와 같이 Multi-scale grouping (MSG)과 Multi-resolution grouping (MRG)를 제시하고 있습니다. MSG는 scale의 변화를 준 sample group을 concatenate한 것이고, MRG는 abstraction을 거친 vector와 raw data vector를 concatenate한 것입니다. 특별히 training point set을 균등하게 분포하고 95%의 분포 확률을 만족하는 범위에서 랜덤하게 뽑는 것을 dropout (DP)라고 말하고 있습니다. 그리고, MSG보다 MRG가 computational resource가 덜 사용하는 장점이 있다는 것을 언급하고 있습니다.
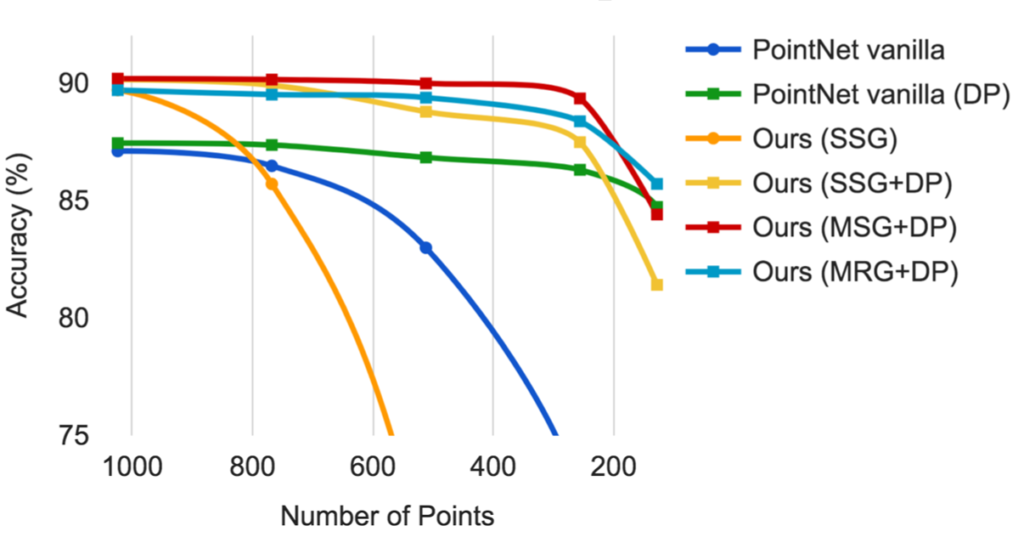
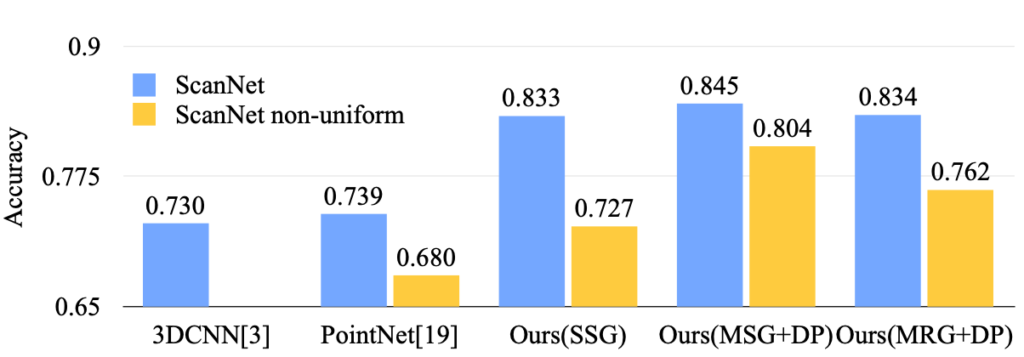
그림 3과 같이 MSG와 MRG를 DP와 같이 사용한다면 points의 개수가 적은 상황, 즉 density가 불균형적인 문제에도 강인한 것을 보여주고 있습니다. 그리고 그림 4는 정확도에 대해 비교하고 있는데 의문이 드는 점은 MSG의 성능이 더 좋은 것으로 나오는데 위에 언급한 바로는 MRG의 효율성이 더 좋다고 말한 점에 대해 정확한 비교 실험 결과가 없다는 것입니다. 논문에서는 MSG와 MRG의 trade-off가 없기 때문에 조금 더 알아봐야할 항목으로 생각됩니다.

표 1은 PointNet++는 ModelNet40 데이터셋의 classification에서 sota를 달성했다는 점을 보여주고 있습니다.
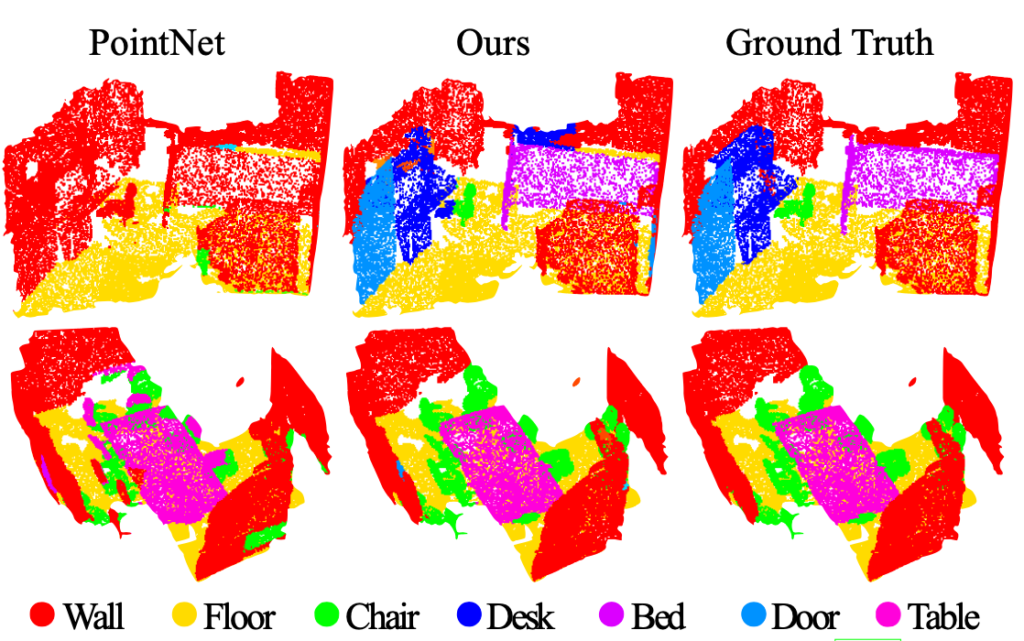
그림 5의 정성적 결과 비교로 PointNet++가 이전 연구에 비해 scene에서 object, 즉 전체에서 부분을 잘 구분해내는지 알 수 있습니다.
PointNet과 PointNet++ 모두 point clouds data라는 raw data만을 사용하여 기존의 2D 베이스의 확장 연구와 다른 방법으로 3D의 classification과 segmentation이 잘 동작하는 방법을 제시하고 있습니다. 이번 PointNet++의 sampling 방법인 FPS에 대해 그런 방법이 있다하고 넘어간 점과 MSG, MRG의 trade-off 결과를 찾지 못한 점에 대해 내용을 보충할 예정입니다.
참고:
[1] PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
좋은논문 리뷰해주셔서 감사합니다. 몇가지 궁금한점이 생겼습니다.
이전 PointNet 리뷰에서 ” point clouds data의 (x, y, z)를 사용하여 k개의 class를 구분할 수 있고, n x m개의 score output으로 subcategory를 결정할 수 있습니다. (n은 point clouds data의 개수, m은 subcategory의 개수입니다.)”라고 이야기하셨는데 해당 논문도 ‘++’이기 때문에 같을것이라고 생각합니다.
제가 궁금한것은 그럼 이러한 raw point cloud data 기반 3D의 classification과 segmentation을 해결하는 Network는 형태가 비슷한 object의 분류가 쉽지 않을것같은데, 해당 문제들에 대해서도 이 논문이 언급하고 있는지 궁금합니다. 제가 이야기하는 형태가 비슷함이란 사람과 마네킹과 같은 object 입니다!
논문에서 질문주신 사항에 대해 언급하진 않았으나 개인적인 소견으로 point clouds data로 형태가 비슷한 물체에 대해 구분하는 것은 이미지로 구분하는 것보다 더 어려울 것으로 생각됩니다. 왜냐하면 성능을 제시한 데이터의 subset은 10개, 40개로 제공되며 예시와 같은 수준의 비슷한 class로 구분되지 않았기 때문입니다.
이 질문에 대해 저자의 자료를 좀 더 찾아보도록 하겠습니다.