
해당 논문은 360도 full-view의 카메라의 등장으로 카메라 종류에 따른 외곡을 효율적인 파노라마 이미지 처리기법을 제안한다.
360도 파노라마 이미지에서 Recognition을 하는데 이미지의 상황을 통한 정보의 정확도향상과 equirectangular images의 특징에 맞는 딥러닝 모델을 사용하여 object detection과 semantic segmentation을 하는 모델이다. 해당 논문은 single spherical RGB image로 부터 object의 localization과 pixel-wise classification을 진행하며 모든 object의 recover instance segmentation masks정보를 3D공간에 구성한다.

논문에서는 다양한 detection모델중에 BlitzNet을 사용하였다 해당 모델은 1stage 모델이며 semantic segmentation정보를 학습하며 pixel다위로 학습을 진행하고 detection과 segmentation의 관계를 학습하는데 효율적이다고 한다. 또한 14개의 다른classes의 indoor세션에서 물체와의 관계를 학습한다고 한다. 사람이 주변환경의 정보를 통해 물체를 인식하는데 도움을 얻는것을 학습에 착안한 방법이라 한다. 또한 해당연구는 3D배치 복구및 3D제해석 하는 연구에 도움이 될것 이라고 한다.
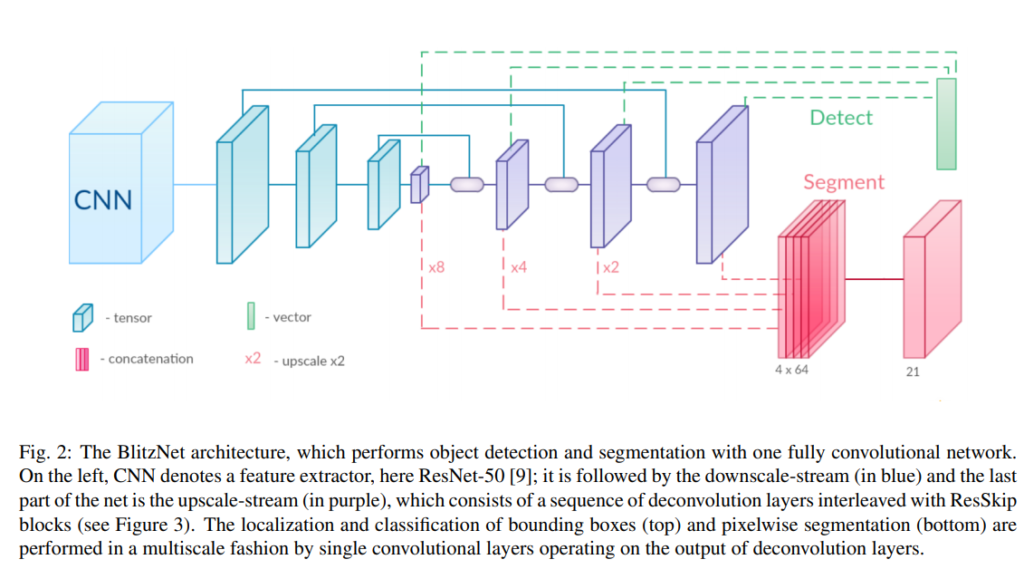
Model – Panoronic BlitzNet
object detection과 semantic segmentation task를 모두 다룬다. BlitzNet에서 주요 변경사항은 입력의 가로세로 비율을 수정, 그에 따른 세로운 앵커박스 제안 – 이때 이미지를 그리드로변환하여 그리드 셀에서 서로다른 object를 관리하도록 서로다른 5개의 비율로 제안한다. 또한 random crops을 제거하고 horizontal rotation을 0도에서 360도까지 360도에서 다른 모든 방향을 포함하는 형식으로 데이터를 증다시켰다.
- How can we deal with 360◦ images distortion?
- “adapts its shape and size accordingly to the distortions” 사물을 인식하는 부분에서 기존의 Convs 를 EquiConvs로 대체하였다. 이때 왜곡의 정도에 따라 kernel의 크기와 형태를 변화시킨다.
- 물체의 왜곡에 강인함을 가지게 되며 카메라의 위치에도 강인함을 갖게 된다.
- “pre-training much more effective” SUN RGB-D데이터셋으로 pre-training을 한후 적용시킴.
- “adapts its shape and size accordingly to the distortions” 사물을 인식하는 부분에서 기존의 Convs 를 EquiConvs로 대체하였다. 이때 왜곡의 정도에 따라 kernel의 크기와 형태를 변화시킨다.
- From semantic to instance segmentation
- ” pixel-wise instance classification “Semantic segmentation masks를 사용하면 object detection을 할때 이미지의 pixel단위로 분류가 가능하다. 그리고 구체적인 object instance를통해 pixel을 3Droom에 제구성된 값을 정확히 배치한다.
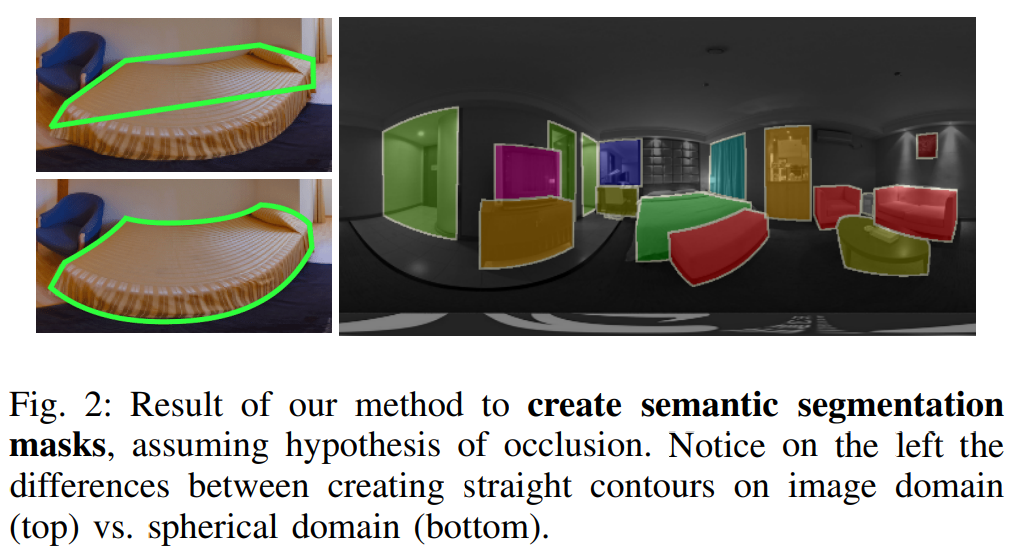
- Can we convert instance segmentation masks into 3D bounding boxes?
- 벽면, 천장, 바닥 도든 영역을 제배치하여 3D형태의 공간을 복구한다.
- ” improve the instance segmentation masks “ 저자들은 일반적으로 바닥에 놓여있는 물체가 아닌 벽에 걸려있는 것과 같은 일반적이지 못한 상황에 대해 segmentation masks를 보안하여 인식 할 수있도로 만들어야 한다고 한다.
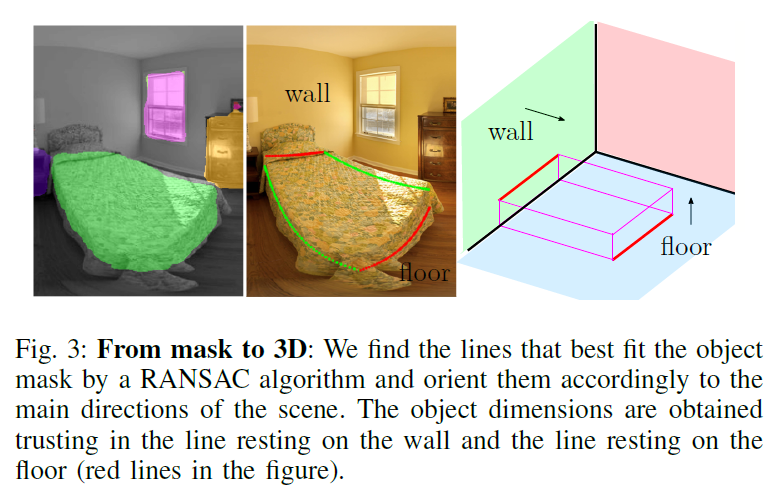
- “place the identified objects inside the 3D model of the room” 해당논문[Corners for Layout: End-to-End Layout Recovery From 360 Images]을 참고 하여 룸의 레이아웃을 얻으며, 실외의 영상은 대부분 직육면체를 이룬다는 “Manhattan World” 가정을 사용한다. 또한 해당논문[ Layouts from Panoramic Images with Geometry and Deep Learning ]을 접근에 따른 장면 소멸지점을 계산한다. 이때 RANSAC기반의 알고리즘으로 최대 5배 빠른 방법론을 사용했다고 한다.
EXPERIMENTS
SUN360확장 데이터셋으로 학습을 진행하였고 Python 3.5에서 Tensorflow v1.13.1 프레임워크로 작성된 코드이며 단일 Nvidia GeForce GTX 1080 GPU환경에서 실험하였다고 한다.
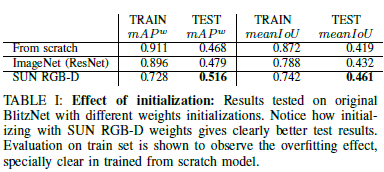
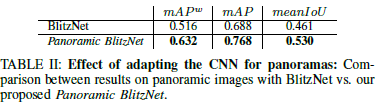

– Instance segmentation post-processing이 적용되었을때의 성능 비교
–

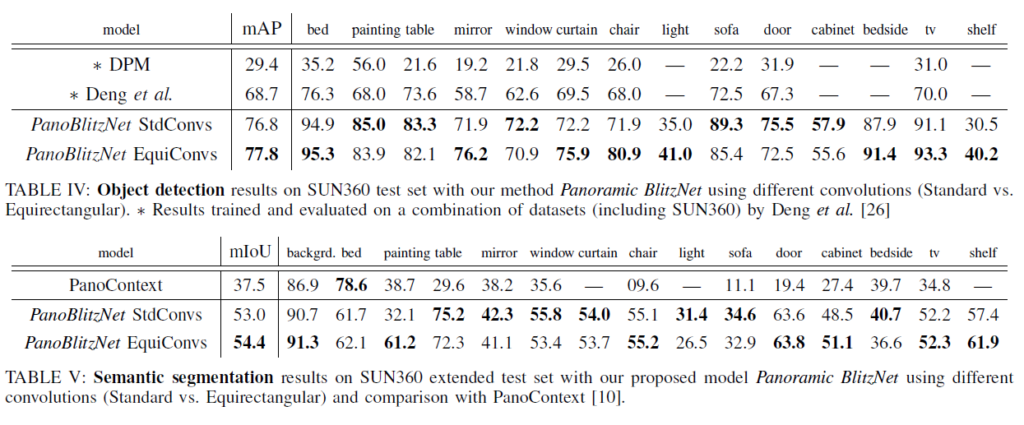
실험 5 – Comparison with the State of the Art
– 본인들이 사용한EquiConvs를 사용하면 더 좋다고 한다.
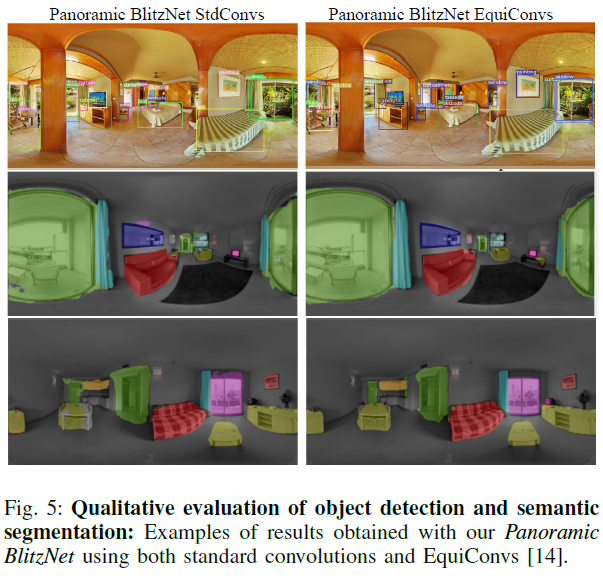
해당논문은 360도 이미지에서 실제 사물에 대해 완전한 이해를 제공하는 방법론을 제안한것 같다. 또한 equirectangular panoramas의 고유특징으로 2D와 3D를 재구성하는것으로 360도 카메라의 넓은 시야에대한 장점을 살릴수 있는 연구 인것 같다.
좋은 리뷰 감사합니다.
궁금한 점이 있는데, Blitz모델에 대한 그림과 주석을 보면 디코딩하는 부분에서 ResSkipBlock을 interleaved했다고 나와있는데, 단순히 해당 디코딩 레이어와 대칭되는 인코딩 레이어의 feature map을 concat했다고 보면 되는 건가요?