
GAN에 대한 논문을 종종 읽어보면 자주 참조되던 논문이라, 이번 기회에 읽고 정리해보고자 가져왔습니다.
Introduction
GAN은 정말 다양한 task에 사용되는 모델입니다. 하지만 이런 GAN의 고질적인 문제가 하나 존재하는데 바로, 우리가 원하는 데이터를 골라서 생성할 수 없다는 점입니다. 그 이유는 바로 Generator의 input을 random noise vector로 하기 때문에 생성되는 영상은 무작위 영상이 되어버리기 때문입니다.
그래서 이 논문에서는, 사용자가 원하는 영상을 생성할 수 있게끔, 기존 GAN에 특정 조건(Condition)을 세팅하자는 것이 키포인트입니다.(그래서 논문 이름도 Conditional Adversarial Network입니다.)
Method
먼저 설명에 들어가는 용어부터 간단히 정리하고 시작하겠습니다.
- z : random noise vector
- y : output image
- x : observed image
- G : generator
- D : discriminator
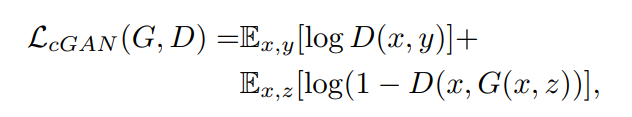
위에 수식은 conditional GAN의 objective입니다. 저 수식은 기존 Discriminator의 loss 식에서 – 부호를 + 부호로 바꾼 것입니다. -부호를 +부호로 바꾼 것이기에, Discriminator는 전체 값이 minimize에서 maximize가 되는 방향으로 바뀌어야 하며, Generator의 경우에는 Discriminator와 적대적이기에, 이와 반대로 minimize가 되는 방향으로 설정됩니다. (보다 자세한 설명은 GAN 논문 또는 이전에 GAN에 대하여 작성한 x-review를 참고하시길 바랍니다.)
여기서 주의깊게 보셔야 할 것은 Discriminator와 Generator에 가장 기본적인 GAN과 달리 모두 x(observed image)가 들어있는 것을 확인하실 수 있습니다.
x에 대해서 조금 더 설명하자면, 기존 GAN에서는 Generator에 단순히 z(random nosie vector)이 input으로 들어갑니다. 그래서 서론에서 말했던 것처럼 사용자가 원하는 영상을 출력으로 만들지 못하였는데, cGAN 경우는 사용자가 원하는 출력을 나타내는 정답 영상을 z와 같이 넣습니다. 이때 이 정답 영상이 바로 x(observed image)입니다.
또한 이전 방법론에서, L2 distance와 같은 traditional loss와 GAN objective를 섞어서 사용하면 좋은 성능이 나온다는 결과가 나왔습니다. 섞어서 사용하게 될 경우 discriminator는 기존과 변한게 없으나, generator의 경우 discriminator를 속이는 역할 뿐만이 아니라, L2를 이용하여 ground truth와 유사하게 되는 작업도 같이 하게 됩니다. 이를 착안하여 이 논문에서는 L2 대신 L1 distance와 cGAN objective를 융합하였습니다. L2 대신 L1을 사용한 이유는 L1이 L2보다 전체적으로 영상을 덜 블러하게 만들기 때문입니다.
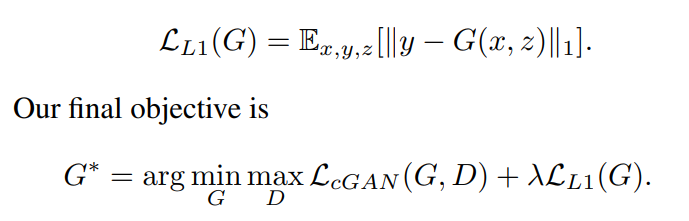
Generator with skips
이제 generator 네트워크가 어떤 식으로 구성되어 있는지 간단하게 살펴봅시다.
Image to Image translation에서 가장 중요한 이슈는 입력 영상을 열심히 변형시켜서 출력 영상을 만들었을 때, 이 출력 영상이 입력 영상과 유사한 퀄리티를 가지고 있는지가 핵심입니다. 예를 들어, 고해상도의 입력 영상을 넣고 변형시켰을 때 똑같이 고해상도의 출력 영상이 나올 것인가?가 중요한 문제였던 것입니다. 하지만 변형이 어떻게 되던간에, 결국 입력 영상과 출력 영상의 근본적인 구조는 대략 유사하게 남아 있기에, 이를 고려하며 Generator를 설계했다고 합니다.
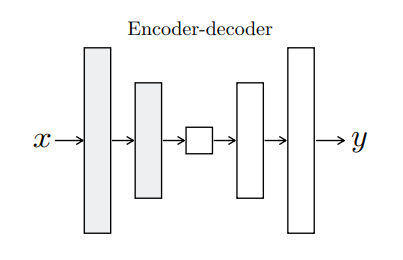
기존에 여러 방법론들은, 위에서 설명한 이슈를 encoder-decoder network를 이용해서 해결하려고 했습니다. 위에 그림을 보시면 알 수 있듯이, 입력 영상을 컨볼루션 연산을 통해 feature map을 줄여나가다가, bottleneck layer에서부터 Transposed 컨볼루션 연산을 통해 feature map을 늘려나가는 것을 말합니다.
하지만 이때 큰 문제점이 발생하는데요, 바로 중앙(bottleneck layer)에 feature map의 크기가 입력 영상의 비해 너무 작아서, 다시 사이즈를 늘려 출력 영상을 만들었을 경우, 정보의 손실이 발생할 수 있다는 것입니다.
이를 해결하기 위해서 이 논문에서는 low-level information을 공유하여 해결하고자 합니다.
예를 들어, colorization(흑백을 컬러로 재생) 작업을 하는 모델을 만든다고 가정해봅시다. 여기서 우리는 말그대로 색감에 대한 새로운 영상을 만드는 것이지, 영상 속 엣지의 위치정보들을 건들지는 않습니다. 즉 입력과 출력은 중요한 엣지의 위치정보들이 변하지 않기에, 이러한 정보를 공유하면 Encoder에서 발생한 정보의 손실을 메꿀 수 있지 않을까? 가 핵심입니다.
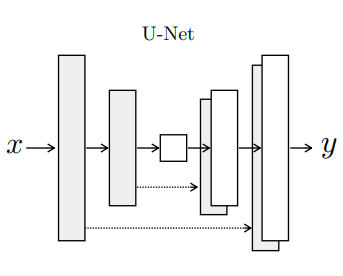
이를 논문에서는 skip connection을 사용해 아주 간단하게 구현하였습니다. 아까 Encoder-Decoder network 그림을 보셔서 아시겠지만 해당 네트워크는 중앙에 bottleneck layer를 기준으로 좌우 대칭으로 이루어져있으며 serial 하게 학습되는 네트워크 입니다. 그렇기에, layer의 갯수가 총 n개라고 가정하면, 1번째 layer와 n-1번째 layer가 같은 사이즈로 대칭이며, i번째 layer와 n-i번째 layer가 서로 대칭인 구조를 이루고 있습니다.
이를 통해 Encoder 단에 i번째 layer의 feature map을 참고하여, Decoder 단에 n-i번째 layer에서 정보 손실을 메꿀 수 있습니다. 실제로 skip connection은 layer i의 모든 채널에 대하여 n-i layer에 concat 해주기만 하면 됩니다.
Markovian discriminator (PatchGAN)

자 이제 discriminator로 넘어와봅시다. 먼저 우리가 잘 아는 L2 loss와 L1 loss는 원본 영상과 생성 영상의 유클리디안 거리를 최소화 하려고 합니다. 이는 곧 영상의 평균 성분인 Low-frequency에 집중하게 되어 영상에 blur가 심하게 생깁니다.
그렇다고 해서 L1, L2 loss가 단점만이 존재하는 것은 아닙니다. 비록 생성되는 영상의 High frequency를 놓치기는 하지만, Low frequency에 대해서는 대부분의 상황에서 매우 정확하게 잡아냅니다. 이는 반대로 말하면, Discriminator에서는 영상이 blur 처리가 되지 않게끔, High frequency만을 집중적으로 보며 해당 영상이 Real 인지 Fake인지를 결정하게끔 설계되면 된다는 것을 의미합니다.(생성 영상의 Low frequency는 L1 loss가 책임지고 있으니깐)
그럼 어떻게 하면 High frequency에 집중하게끔 Discriminator를 설계할 수 있을까요? 기존에 Discriminator는 영상 전체에 대하여 score를 구해 영상의 Real/Fake 여부를 결정하였습니다.
하지만 해당 논문에서는 High frequency를 위해, Discriminator가 일정 영역으로 patch를 나누어서 Real/Fake 여부를 확인합니다. 이를 통해 Real/Fake로 분류된 Patch의 갯수를 평균내어 스코어를 계산하는데, 이 방식이 바로 PatchGAN입니다.
영상의 전체가 아닌 Patch 단위로 영상의 Real/Fake 여부를 판단하는 것이 성능의 문제가 있을 수 있지 않을까? 라고 생각하실 수도 있습니다. 하지만 사실 특정 픽셀로부터 일정 거리이상 떨어져있는 픽셀은 서로 간에 개연성이 떨어지기에 오히려 독립적으로 볼 수 있게됩니다. 게다가 patch 영역으로 계산하기에, 더 적은 파라미터를 사용하고, 연산 속도도 빠르다는 장점이 생깁니다.
논문에서는 영상 전체에 대하여 score를 계산하는 기존 Discriminator의 방식을 ImageGAN이라 표현하였고, 하나의 픽셀 단위로 score를 계산하는 것을 pixelGAN이라고 표현하였습니다.
위에 그림1을 살펴보시면, L1은 blur가 생긴 것을 확인할 수 있고, pixelGAN에 경우에는 채도가 증가하신 것을 볼 수 있습니다. ImageGAN에 경우에는 영상의 퀄리티가 전체적으로 떨어지는 것을 확인할 수 있습니다. 해당 논문에서는 실험적 결과를 통해 patch size가 70 × 70일 때 가장 좋은 성능을 낸다고 제시합니다.
다양한 task에서의 Conditional GAN 결과 영상을 올리고 마무리하겠습니다.



1. 최종 loss의 후속 term인 \lambda L_{L1}(G)는 regularization을 해주는 것으로 보이는데요. L2대신 L1을 썼다는 것은 수렴하는 방향이 가장 연관성 없는 차원 or 축을 제거하는 방식이므로 작은 값을 가지는 것을 무시하기에 덜 블러하다고 한 것 같습니다. 그런데 최종 loss에서 L1보다 L2의 사용 이유가 덜 블러하다는 것을 언급하면서 그림 1 다음 문단에서는 L1과 L2 모두 블러하다고 언급한 것 같습니다. 추가 설명 부탁드려요.
2. 기존의 GAN 리뷰를 참고하기 위해 글의 링크를 제공하거나 최소한 tagging을 한다면 찾아보기 더 쉬울 것 같습니다.
좋은 댓글 감사드립니다.
L1과 L2 정규화로 인한 블러에 대해서 말씀드리면, 본 리뷰에서는 자세히 안적었지만 사실 논문에서는 GAN 에 대한 얘기를 하기 전에, CNN을 통한 영상 처리 및 변환에 대해서 언급을 합니다.
기존에 CNN은 흔히 L1 또는 L2 loss를 loss function으로 사용하여 학습을 하였습니다. 이때 CNN은 사용자가 원하는 영상을 나타내도록 학습하는 것이 아닌 단순히 loss가 최적화 되는 방향으로만 학습이 되는게 문제라고 저자는 말합니다. L1 또는 L2 loss를 최소화한다는 뜻은 gt와 predicted pixel 값 사이에 유클리디안 거리를 최소화 하는 것으로 볼 수 있습니다.
이 떄 이 유클리디안 거리를 최소화 하기 위해서 모델은 모든 predicted 출력값들을 평균화하는 방향으로 학습하게 되고 이러한 영상의 평균화는 곧 영상의 blurring을 발생시킵니다.
그러므로 L1 loss와 L2 loss 모두 영상이 blur해지기에 그림1 부분에 두 방식 모두 블러하다고 표현을 한 것입니다. 그리고 위에 L1이 L2보다 덜 블러하다라는 내용은 저도 자세히 알지는 못하지만, 논문의 저자가 L1과 L2 모두 사용하여 실험을 해봤을 때 L1이 조금 덜 블러하다라고 언급하였습니다.
요약하자면 L1과 L2 모두 유클리디안 거리를 최소화하는 방향으로 학습되다 보니, 출력 영상을 평균화 시켜서 영상이 blur해진다고 보시면 될 것 같습니다.
그리고 이러한 블러를 방지하고자, skip connection을 추가한 U-net을 사용하고, Discriminator에서는 패치 영역으로 영상의 Real/Fake 여부를 확인하게끔 학습하여, Generator가 블러된 영상이 아닌 디테일이 살아있는 영상을 만들게끔 학습하도록 유도하는 것입니다.
다음 리뷰에서는 2번에서 적어주신 피드백을 참고하여 올리도록 하겠습니다:)
rgb를 thermal로도 변환 가능할 것 같은데 이에 대한 내용은 따로 없나요?