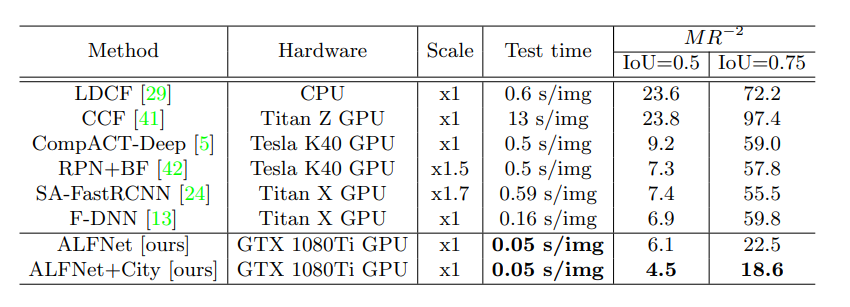
해당 논문은 Pedestrian detection에 특화된 SSD 계열(1stage detection)의 방법을 제안했다. 또한 RetinaNet의 컨셉을 anchor box를 통한 regression과 class에 대한 confidence score에 적용함(Asymptotic Localization Fitting, 이하 ALF-module or ALFNet)으로써 성능 향상을 얻었다.
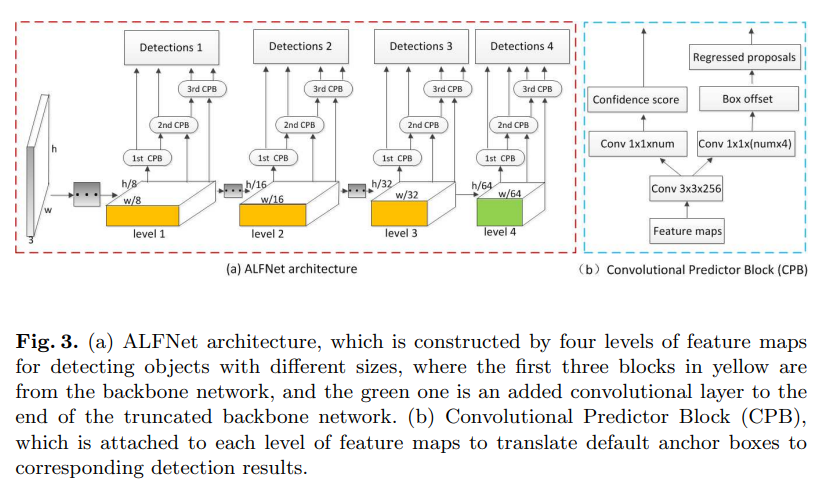
ALFNet의 핵심 모티브는 1 stage(SSD 계열)의 빠른 속도와 2 stage(faster-rcnn 계열)의 높은 정확도를 동시에 얻으며 특히 높은 IoU threshold에서 높은 성능을 얻고자 하는 것에 있다.
저자가 말하길 2 stage(Rcnn 계열)는 Region Proposal Network(RPN)(:anchor box(region)에 대한 네트워크, 동일한 크기의 박스들이 담긴 sliding window를 이동시키며 class와 region를 계산/생성)과 ROI Pooling을 이용하여 높은 성능을 얻지만, 많은 계산량 때문에 속도가 느린 단점이 있다고 말한다.
1 stage(SSD 계열)은 RPN 없이 바로 default anchor box로부터 regression과 classification을 진행하여 낮은 연산량으로 빠른 속도를 얻지만 2 stage 계열에 비해 느린 성능을 보인다고 한다.
저자는 빠른 속도와 성능을 가진 detection을 얻기 위해 Fig 3.의 architecture를 제안하였다. 해당 아키텍쳐는 cascade faster rcnn와 매우 유사한 형태를 가진다. 즉 2 stage의 RPN을 이용하여 성능 향상을 기대하였다. 하지만 cascade faster rcnn와 차별점이 있다. 각 anchor box의 regression은 1 stage의 방법을 이용하여 계산량 줄여 속도를 향상을 기대하였다. 또한 보다 성능을 향상 시기키 위해 Fig 3.의 Convolutional Predictor Block(PCB)를 anchor box에 대한 regression 연산을 강화시켜 높은 IoU를 가진, 즉 높은 성능을 가지면서 빠른 속도를 가진 네트워크를 구조를 제안하였다.
구체적인 방법은 아래와 같다.
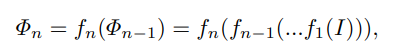
- I : input 영상
- \mathit{\Phi} : feature map of n-th
- f : layer of n-th
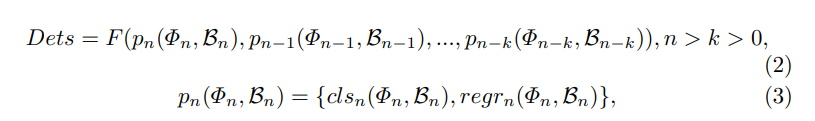
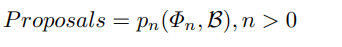
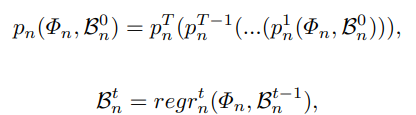
- \mathcal{B} : anchro box
- p : predictor, box regression & classification
Overall Framework
- Backbone은 ResNet-50, MobileNet에 대한 성능지표가 제시되었으며, 기본적으로 ResNet-50을 기본으로 실험을 진행하였습니다. ResNet-50일 경우 level(layer) 3, 4, 5 (Fig 3.의 초록색 박스) 를 사용하였으며, 추가적으로 level 6(Fig 3.의 노란색 박스) 을 추가하여 사용했습니다.
- default anchor box의 크기는 {(16, 24),(32, 48),(64, 80),(128, 160)} 이며, aspect ratio는 0.41로 설정했습니다.
- Loss
- regression loss(anchor box)는 L1 loss를 사용했으며, faster-RCNN과 동일한 방법을 사용
- classification loss는 binary cross-entrophy loss를 사용했으며, /alpha = 0.25 /gamma = 2 로 설정했습니다.
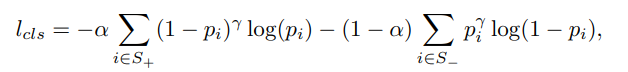
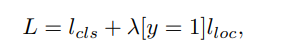
Experiments
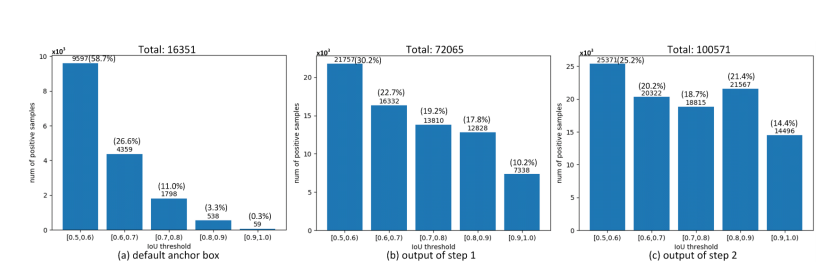
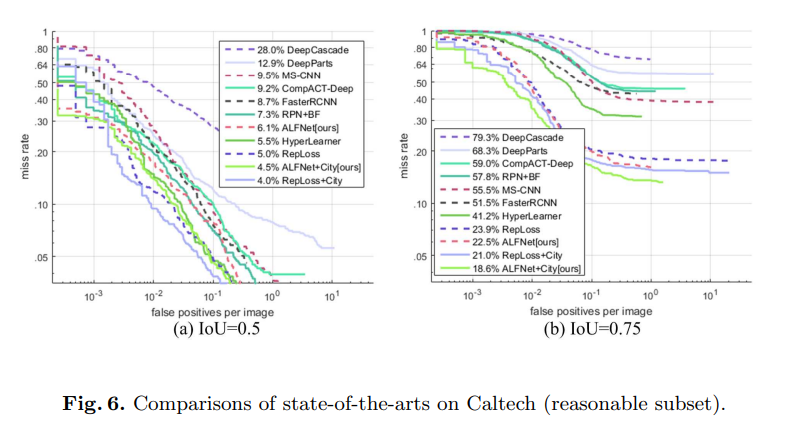
해당 논문들은 제안한 ALFModule, PCB를 추가함으로써 성능의 향상을 보여주는 지에 대한 실험과 결과를 보여주였습니다. 위의 Fig 4.를 보시면 PCB를 추가함으로써 기존 default box로만 regression을 할 때보다 IoU threshold 0.5 보다 높은 값에서도 postive의 비율이 향상될 것을 확인할 수 있습니다.