

이전부터 Computer vision에서 영상의 keypoint 를 추출하는 것은 자주 풀어오던 문제였습니다. 주로 handcraft 알고리즘이라고 불리우는 전통적인 알고리즘들은 keypoint 의 위치를 detect 한 뒤, 특징을 표현하는 describe 과정을 거쳤습니다. 그러나 최근 describe-detect 순서로 keypoint를 추출하는 딥러닝 기반 방법론들이 나타나게 되었습니다. 우선적으로 CNN backbone network를 통해 전체 영상을 describe 하고, describe 된 feature map으로 detect 를 하는 방식으로 이루어지게 됩니다. 이번에 소개할 D2D도 이와 같으며 contribution을 요약하자면 다음과 같습니다.
- D2D는 학습이 필요하지 않기에 어떤 CNN base discriptor에도 사용할 수 있습니다.
- Feature map의 공간적이고 깊이적인 정보를 사용해 relative saliency와 absolute saliency 측정 방식을 제안했습니다.
- 다른 방식에 적용하여 성능이 올라간 것을 실험했습니다.
1. Describe-to-Detect
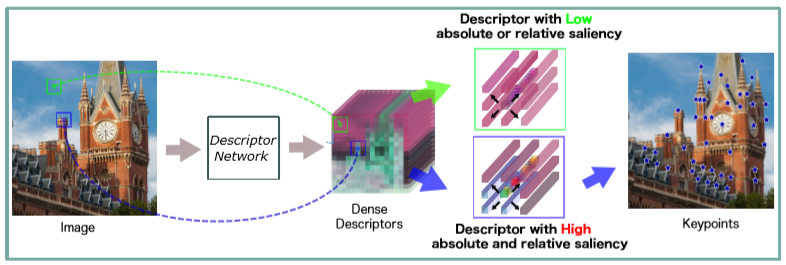
1.1 Keypoint 란?
본 논문에서 keypoint 를 정의하기 위해 다음과 같은 가정을 세웠습니다.
가정 1. 어떤 keypoint 의 descriptor 가 매우 유용하다면 그 keypoint 는 absolute saliency를 지닙니다.
가정 2. 어떤 keypoint의 descriptor 가 주변부 픽셀들과 매우 잘 구별된다면 그 keypoint는 relative saliency를 지닙니다.
가정에서 알 수 있다시피 absolute saliency 는 descriptor 의 정보량에 대해, relative saliency 는 이웃 픽셀들과의 관계에 대해 논문에서 정의한 용어입니다. 가정 1의 경우, 영상의 모양과 질감의 상당한 변화가 있으면 absolute saliency 를 지닌다고 할 수 있습니다. 그러나 주변부 픽셀과 구별성이 없다면 keypoint 를 구별하기 쉽지 않기에 가정 1만으로는 충분하지 않고 가정 2도 만족해야 좋은 keypoint 라고 할 수 있게 됩니다. 그래서 논문의 저자는 좋은 keypoint 를 얻기 위해서는 가정 1에 대해 판단하고 만족한다면 가정 2 까지 만족해야한다고 소개합니다.
1.2 Keypoint 를 detect 하는 방법
- Absolute saliency 측정 방법
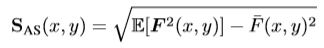
Binary 한 상황에서 entropy 가 높은 것을 택하는 것이 좀 더 compact 하고 robust 하게 장려한다는 것을 이전 논문들에서 밝혀왔습니다. 이러한 이유에서 저자는 n차원 descriptor 의 entropy 로 정보량을 측정하는 방식을 택하였습니다. 그러나 binary 한 상황에서와 달리 실제 descriptor 에는 미분가능한 entropy 가 필요로 한데, 이는 연산량이 많기에 binary 한 상황에서처럼 표준 편차를 entropy 추정에 활용하였습니다. (1)에서 \overline{F}(x,y) 는 F(x,y) 의 평균을 나타냅니다.
- Relative saliency 측정 방법
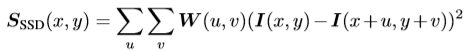
가정 2를 확인하기 위해 현재 값고 주변 값 사이의 관계를 측정할 때는 autocorrelation 을 사용합니다. Handcraft 알고리즘인 Moravec corner detector와 Harris detector 에서도 이를 사용했었습니다. 이러한 autocorrelation 을 sum of squared differences (SSD) 로 식 (2)와 같이 구현되게 됩니다. I(x, y) 는 pixel intensity 이며 (u, v) 는 (x, y) 중심의 window index를 의미합니다. 만약 S_{SSD}(x, y) 의 값이 크다면 주변과 낮은 유사도를 지니는 것을 의미합니다. 저자는 SSD 에서 pixel intensity 부분을 dense 한 descriptor 로 대체 하였으며 다음과 같이 변경하였습니다.
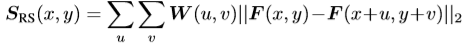
여기서 S_{RS}(x, y) 의 값이 크다면 높은 relative salienct 를 지닌다고 할 수 있습니다.
- D2D score
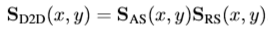
제안된 두 가지의 측정 방식에서 나온 값을 곱하여 식 (4)와 같이 score 를 측정하게 됩니다.
2. Experiments
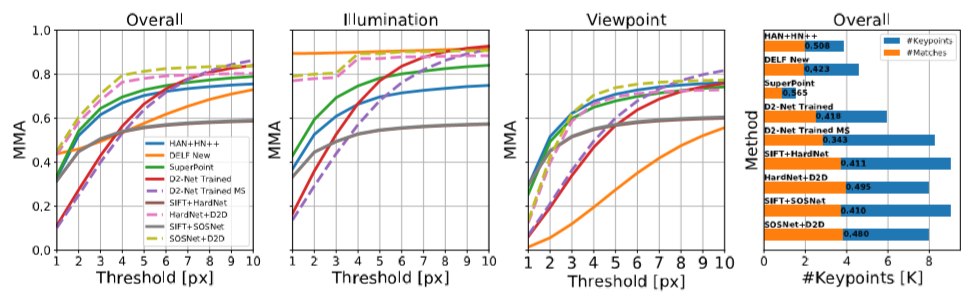
제안된 방법을 기존 존재하는 local descriptor 를 추출해 내는 방법론에 적용했을 때 특히 중요하다고 말할 수 있는 5px 미만의 threshold 구간에서 다른 방법론들 보다 높은 성능을 나타내었습니다.
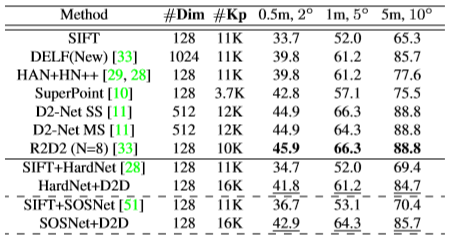
그리고 Table 1 에서 기존 성능이 떨어지던 방법론에 적용을 했을 때 SOTA 와 유사한 성능을 낸 것을 확인할 수 있습니다.
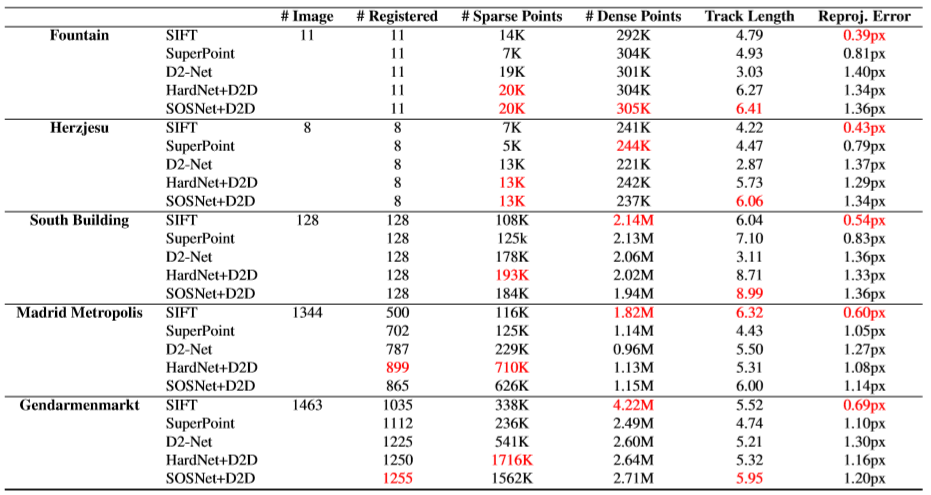
Table 2에서도 마찬가지로 ETH dataset 에서 SfM 으로 평가했을 때 SOTA 방법론들과 유사한 성능을 낼 수 있는 것을 확인할 수 있습니다.
일반적으로 알고 있던 detector, desciptor 순서가 아니고 기존에 연구된 descriptor를 사용하여 key point를 detect한다는 개념인가요? 그리고, 학습이 필요없다는 점에 대한 설명이 부족한 것 같습니다. 식 4의 absolute silency와 relative silency를 곱한 score가 어떤 역할을 하게 되는 건가요?