
깃허브 및 페이퍼
배경지식
https://nlpinkorean.github.io/illustrated-transformer/
설명
이번에 페이스북AI에서 제안하는 DE:TR 모델은 기존 Object Detection의 프레임과는 완전히 다르다. DE:TR은 NLP에서 사용되는 Encoder-Decoder transformer 를 Object Detection으로 가져왔고, COCO 데이터셋에 대해서 평가한 결과 기존 Faster-RCNN 기반 네트워크들과 비슷한 성능을 나타냈다. 또한 DE:TR은 large object에 대해서는 확실한 성능 개선이 나타났다.
네트워크 구조

위의 구조는 DE:TR:의 구조이다. 가장먼저 백본(Resnet50,101) 이미지에 대한 피처를 추출한다. 그리고 이 추출한 피처를 가지고 positional encoding과 함께 NLP에서 사용하는 transformer encoder 입력으로 들어가게 되는데, 이때 이미지는 시퀀스 데이터가 아니다. 이를 시퀀스 데이터와 같이 표현하기 위해서 다음과 같은 작업을 거친다.
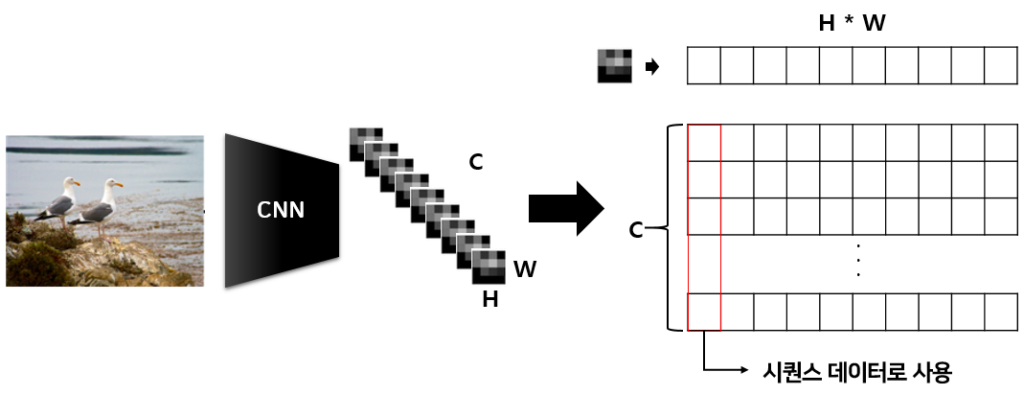
이렇게 만든 시퀀스 데이터를 NLP에서 사용하듯 Transformer encoder에 입력하면 된다. Transformer encoder에서는 이렇게 입력된 시퀀스 데이터간의 self attention을 통해 새로운 벡터를 만들게 된다. 이와 관련된 내용은 맨위의 배경 지식을 통해 공부하길 바란다.
자 그럼 이렇게 만든 encoding vector를 가지고 Transformer decoder에서는 또다른 시퀀스 데이터를 만들게 되는데, 기억해야할 것은 Transformer decoder 은 입력가 동일한 시퀀스 데이터를 생산하며 이 과정에서 인코딩 벡터를 사용하는것이다. 위의 그림에서는 4개의 object queries(시퀀스 데이터)가 입력으로 들어가 4개의 out put이 나오는 것을 확인할 수 있다. 입력과 동일한 out put이 나오며 이는 최종적으로 object detection에서 모델이 찾을 수 있는 최대 object의 수와 동일하다. 그러므로 적절한 object queries를 설정해주는 것이 중요하다. 또 한가지 특징은 여기서 object queries는 특별한 값이 아닌 랜덤 벡터라는 점이다. Transformer decoder 구조를 입력하는 것이기 때문에 내가 원하는 output의 값을 입력으로 넣으면 결국 최종적으로는 class와 box의 정보를 얻을 수 있는 데이터를 인코딩 벡터의 값들을 통해서 만들어낼 수 있다.
이렇게 Transformer decoder 가 만들어낸 시퀀스 데이터는 마지막으로 classifier 역할을 수행하는 FFN을 통해 classification과 bbox의 값을 나타구한다. 여기서 FFN은 정규화된 박스의 중심좌표, 그리고 박스의 가로, 세로 값을 예측한다. 또한 softmax를 통해서 class label에 대해서도 예측하게 된다.
이에 대한 모델의 더 자세한 구조는 다음 그림과 같다.
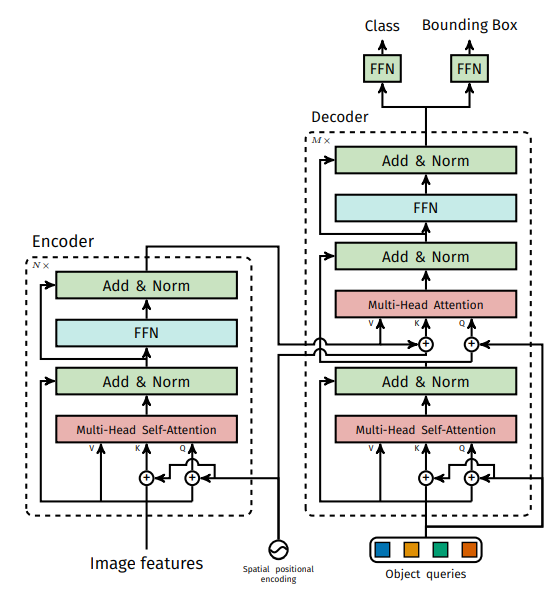
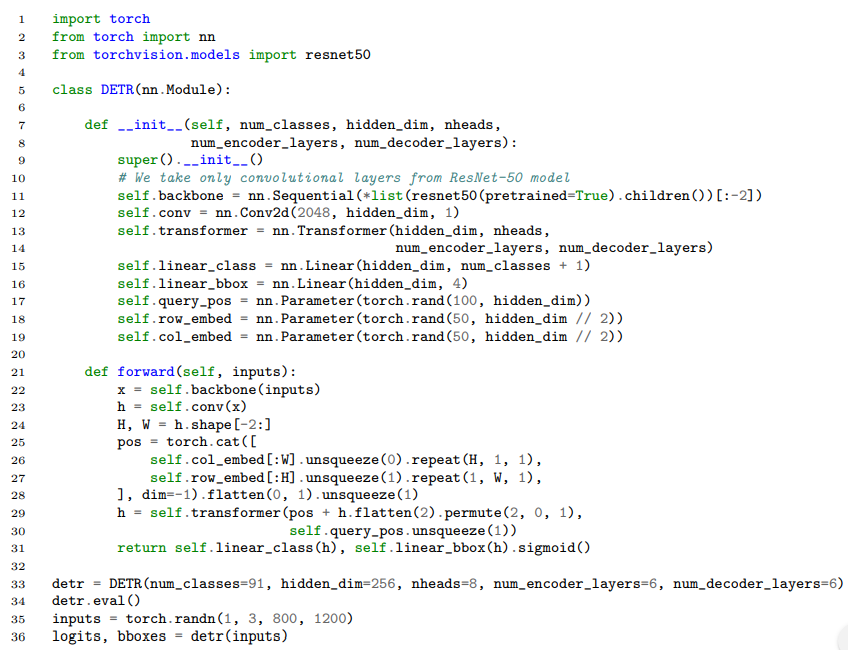
자 그렇다면 이러한 네트워크의 전체적인 구조를 알아봤다. 실제 이를 파이토치 코드로 작성하면 다음과 같이 정말 매우 너무 심각하게 심플하다.
Loss 설계
자 그럼 기존 NLP에서 사용하던 Transformer 구조를 Object Detection으로 처음 가져온 이 논문, 그럼 Object Detection을 위한 Loss 설계는 어떻게 수행했을까??? 가장 논문에서도 핵심인 Object detection set prediction loss에 대해서 알아보자.
앞서 구조 설명할때 transformer encoder는 내가 설정한 Object queries와 동일한 숫자의 시퀀스 데이터를 만든다고 설명했다. 즉 내가 하나의 이미지당 N개의 Object를 예측하겠다고 설정하면 실제 이미지의 Object가 N개 이상이여도 N개만 예측하고 N보다 작아도 심지어 1개라도 N개의 결과를 만들어 낸다. 모델은 항상 N개의 예측을 수행하게 되고, 실제 GT는 영상속 사람이 어노테이션한 GT와 클래스 정보 그리고 만약 N개보다 작다면 나머지는 배경클래스에대한 정보로 설정해 N개를 맞춘다.
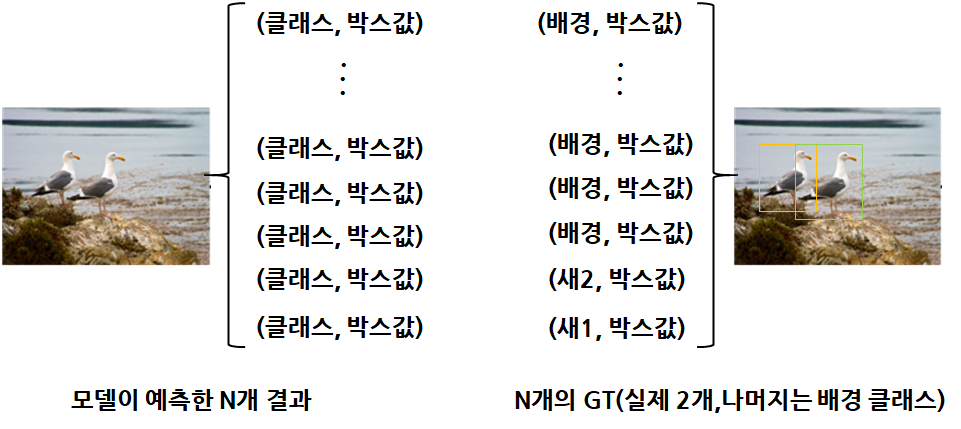
그리고 여기서 다음과 같이 모델의 예측값과 GT의 값을 한 쌍으로 만들어 각각에 대한 Loss를 계산한다.
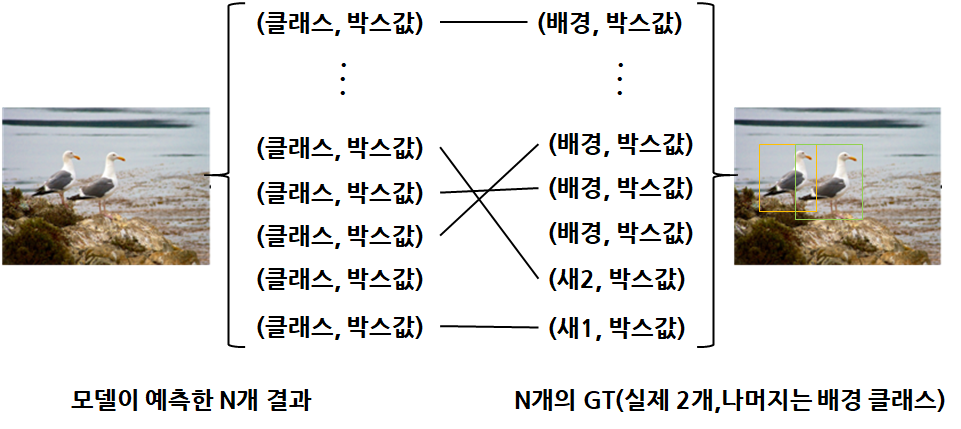
다만 이렇게 다양한 조합으로 쌍을 만들고 모든 경우의 수에 대해서 계산을 수행하는 것은 비효율적이기 때문에 다음과 같은 수식을 만족하는 예측 데이터와 GT데이터의 조합을 결정하게 된다.
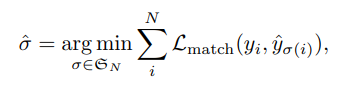
풀어서 설명하면, L_(match)는 두 조합에 따른 loss를 이야기하며 이때 y_{i}는 GT 튜플을 y_{sigma(i)}는 prediction 튜플을 의미한다. 각 조합들의 모든 loss를 더한 값이 최소가되는 조합을 구하면되는데 여기서는 헝가리안 알고리즘을 사용한다. 헝가리안 알고리즘은 배경지식에 관련 링크를 추가하였다. 그리고 L_(match)에 대해서 더 디테일하게 설명하자면, y_{i}와 y_{sigma(i)}는 클래스 정보, 클래스에 대한 스코어, 그리고 박스의 값이 들어있는 튜플이다. 이를 통해서 cost 계산은 다음과 같은 수식으로 계산할 수 있다.
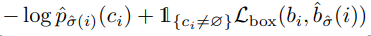
따라서 정리하면 헝가리안 알고리즘에 따른 L_(match) 수식은 다음과 같다.
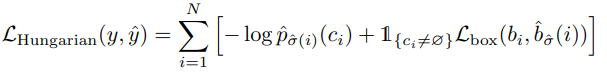
그리고 여기서 박스에 대한 cost를 계산하기 위해서 논문의 방법은 L1 loss와 generalize IoU loss를 결합해서 사용하고, 이를통해 scale-invariant 만들 수 있다. 다시 정리해서 수식화하면 다음과 같다.
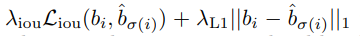
실험결과
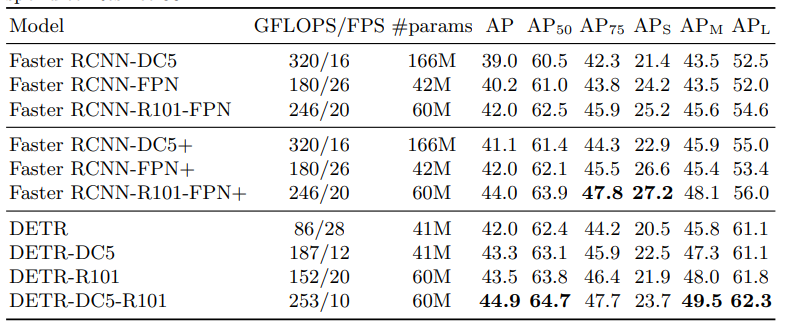
논문에서는 기존 Object Detection과는 다른 완전히 새로운 방법의 Object Detection 프레임워크를 설명하고 있고, COCO 데이터셋을 기준으로 평가한 결과 해당 프레임워크가 기존 제안된 Object Detection과 견주어도 경쟁적임을 실험을 통해서 나타내고 있다. 또한 추가적으로 간단한 네트워크에 적은 파라미터 사용으로도 충분한 성능이 나타나는것을 증명하고 있으며 이에대한 정리 표는 다음과 같다.
또한 다양한 Ablations study를 통해 현 프레임워크에서 최상의 조합을 실험을 통해 나타내고 있다. 자세한 내용은 해당 논문의 Experiments 부분을 참고하길 바란다.
리뷰
기존 Object Detection에서 RCNN, YOLO, SSD 총 3가지의 큰 가지가 존재하였고, 최근에는 Anchor free 방식의 다양한 Object Detection 네트워크들이 개발됐다. 하지만 이 논문은 그러한 틀에 벗어나서 NLP를 Object Detection에 적용하여 심플한 방법으로 좋은 성능을 나타냈다. 흔히 도메인이 다르다 혹은 연구분야가 다르다 라고 이야기를 많이하는데 다른 도메인 다른 분야의 연구도 꾸준히 팔로우업해야하는 이유를 이 논문을 읽으며 알 수 있었다. 그리고 이러한 연구를 할 수 있으니까 FAIR와 같은 메이저 그룹에 속하는구나라는 것도 알 수 있었다.
현 논문의 프레임워크는 다른 채널의 피처의 attention을 구하고 이를 통해서 Object Detection을 수행한다. 이는 다양한 도메인을 fusion하여 Object Detection을 수행하는 연구에게 희소식이지 않을까 생각한다. 기존에는 어떤 feature를 fusion하고 어떻게 fusion해야하는지 사람이 생각해 모델을 설계하였다면, 해당 방법론을 통하면 다른 도메인의 feature라고 할지라도 이 모델이 다른 도메인들간의 feature를 포함해 사람은 알지 못하지만 딥러닝을 통해 feature의 조합, 결합을 만들어내고 이를 통해서 Object Detection을 수행하면 더 좋은 결과가 나타나지 않을까 생각했다.
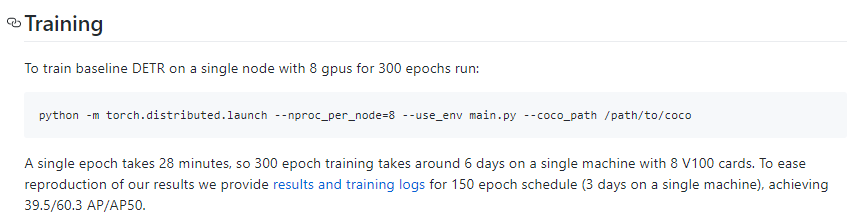
모델 학습에 너무 많은 시간과 스펙이 필요한건 단점인거 같다.
DE:TR을 더 잘설명한 유튜브 강의(코드 및 페이퍼)