https://arxiv.org/abs/2004.10934
Abstract
CNN의 정확도를 높이기 위한 많은 방법들이 존재한다. 이러한 방법들 중 일부는 특정 모델 혹은 특정 데이터셋에서만 잘 작동하는 반면에 Batch Norm이나 Residual connection과 같은 방법은 대부분의 모델, TASK, 데이터셋에서도 사용이 가능하다. 이 논문에서는 Weighted-Residual-Connection(WRC), Cross-Stage_Partial-Connection(CSP), Cross mini-Batch Normalization(CmBN), Self-adversarial-training(SAT) and Mish activation 방법들이 universal 방법이라 가정하고 이들의 조합으로 Tesla V100을 기준으로 ~65FPS의 실시간 속도에서 MS COCO dataset에서 SOTA를 달성했다고 한다.
Introduction
최근 좋은 정확도를 보이는 최신 Object Detection 모델들은 실시간으로 작동하기 힘들고, 학습과정에서도 large mini batch size로 훈련하기 때문에 많은 양의 GPU를 요구한다. 하지만 논문에서는 기존 GPU의 환경에서도 실시간으로 작동이 가능하고 학습과정에서도 1개의 GPU만 요구하는 모델을 제안하고 있다. 논문의 주요 contribution은 다음과 같다.
- 효율적이고 강력한 object detection 모델을 개발하였고, 이 모델은 누구나 1080Ti, 2080TI와 같은 기존 GPU환경에서도 학습할 수 있다.
- object detection 모델 학습과정에 SOTA를 달성한 Bag of Freebies(BOF)와 Bag of Special(BOS) 방법들이 어떠한 영향을 나타내는지 확인했다.
- 기존 SOTA의 방법들(CBN, PAN, SAM 등등)을 하나의 GPU환경에서도 학습이 가능하도록 더 효율적이게 수정하였다.
Related work
Bag of Freebies(BoF)
BOF는 오직 훈련 전략만 바꾸거나 training cost만 늘리는 방법을 이야기한다. Object Detection에서 대표적인 예시로는 Data Augmentation이 있다.
Bag of Special(BoS)
약간의 inference cost 증가로 object detection의 성능향상을 가져오는 post processing이나 plugin module을 의미한다. pulgin module에는
- enlarging receptive field(SPP, ASPP, RFB)
- introducing attention mechanism(SE, SAM)
- strengthening feature integration capability(Skip connection, SFAM, ASFF, BiFPN)
이 있고, post processing에는 모델이 예측한 결과에서 선별하는 방법(NMS, DIoU 등 )이 있다.
Methodology
실시간 객체 검출의 두가지 옵션은 다음과 같다.

Selection of architecture
아키텍처를 선택하는데 있어서 가장 중요한 목표는 input network resolution, convolutional layer number, parameter number, the number of layer outputs 사이의 최적의 균형을 찾아내는 것이다.
많은 연구를 통해서 Object classification을 위해서는 CSPResNext50이 CSPDarknet53과 비교해 더 우수하다는게 증명됐지만, MS COCO 데이터셋에서의 Object Detection에서는 CSPDarknet53이 CSPResnNext50보다 좋은 성능을 나타낸다. -> CSPDarknet53을 선택
다음 목표는 Receptive field를 넓히는 additional blocks과 최적의 parameter aggregation 방법( from different backbone levels for different detector levels (e.g. FPN,PAN,ASFF,BiFPN))을 선택하는 것 이다. 이때 classification에 최적화된 reference 모델이 항상 detector의 최적화된건 아니며, detector의 최적화를 위해서는 아래 조건들이 요구된다.
- (small object detecting을 위한) Higher input network size (resolution)
- (크기가 증가된 네트워크 input을 커ect detecting을 위한) Higher input network size (resolution)
- (크기가 증가된 네트워크 input을 커버해야하는 higher receptive field를 위한) More layers
- (단일 이미지로부터 서로 다른 크기의 object를 검출하는 모델의 능력을 증가시키기 위한) More parameters
논문에서는 더 넓은 receptive field 와 더 많은 파라미터를 갖는 모델을 백본으로 선정했고, 이와 관련된 내용은 아래 표와 같이 정리된다.

CSPResNext50은 16개 conv layer와 425×425 receptive field 그리고 20.6M의 파라미터수를 갖으며, CSPDarknet53은 29개 convlayer와 725×725 receptive field 그리고 27.6M의 파라미터수를 갖는다. 이론적 정당성과 수많은 실험결과 CSPDarknet53이 백본으로 최적의 모델이라고 논문에서 이야기하고있다.
다른 receptive field size에 따른 영향을 요약하면 다음과 같은데,

따라서 CSPDarknet53에서 receptive field를 넓히기 위해 SPP block을 추가했다고 한다. 이때 context feature는 분리해 모델의 속도 감소는 거의 없었다고 한다. 또한 YOLOv3에서는 FPN을 사용했지만 해당 모델에서는 parameter aggregation 방법으로 PANet을 사용했다고 한다. 정리하면 YOLOv4의 구성은 다음과 같다.

이 모델은 누구나 SOTA outcome을 기존 GPU(1080TI, RTX2080Ti)로도 재현할 수 있다.
Selection of BoF and BoS
Object detection의 성능 향상을 위해서 학습과정에 사용되는 방법들은 다음과 같다.

일단 Activations에서는 PReLU나 SELU는 학습이 어렵고, ReLU6는 Quantizationi 네트워크를 위한 방법이기에 이 방법들은 고려하지 않았다. 다음으로 Regularization 방법으로는 Drop Block을 제안한 논문에서 다른 방법들을 이겼다고 해서 그냥 Drop Block을 사용했다. Normalization 방법으로는 학습과정에 단 하나의 GPU만 사용하므로 syncbN은 고려하지 않았다.
Additional improvements
단일 GPU를 가지고 학습이 가능한 detector를 만들기 위해 저자가 사용한 추가적인 방법은 아래와 같다.
- Mosaic, Self Adversarial Training(SAT)이라는 새로운 Data Agumentation을 추가하였다.
- Genetic algorithm을 적용해 최적의 하이퍼 파라미터를 구했다.
- 기존에 존재하는 몇가지 방법(SAM, PAN, CmBN)을 더 효율적으로 학습과 detection이 가능하다록 변경하였다.
Mosaic

2개의 이미지가 섞인 CutMix와 다르게 Mosaic은 학습과정에서 4개의 이미지를 하나로 섞었다. 이로인해 모델은 normal context외의 object를 탐지할 수 있게 된다. 추가로 batch normalization은 각 레이어에서 4개의 다른 이미지로부터 activation statistics을 계산했기 때문에 large mini batch size없이도 그러한 효과를 나타냈다.
Self Adversarial Training(SAT)
Self Adversarial Training(SAT)은 2단계의 forward-backward로 작동되는데, 첫번째 단계에서는 네트워크는 weight가 아닌 original image를 변경한다. 이를 통해서 네트워크는 스스로 adversarial attack를 수행하게 된다. 두번째 단계에서는 일반적인 방법으로 첫번째 단계에서 변형된 이미지에서의 객체를 검출하는 훈련을 수행한다.
CmBN
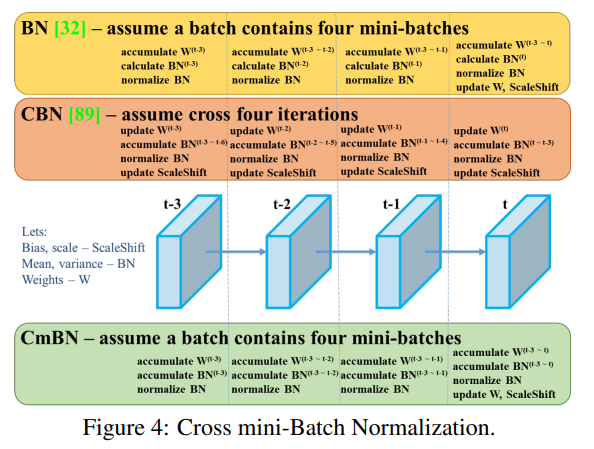
CmBN은 CBN의 변형 버전으로 sigle 배치에서 미니 배치간의 statistics 를 수집한다.
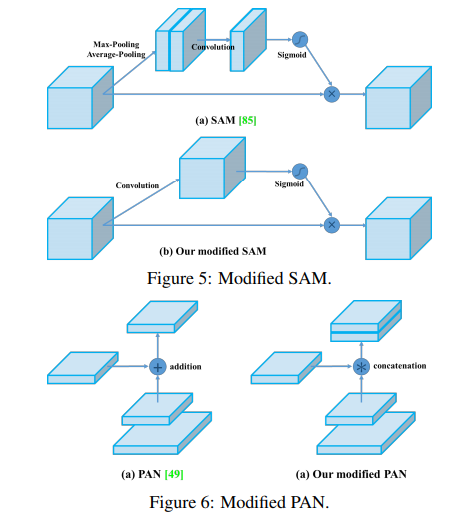
SAM & PAN
SAM의 spatial-wise attention을 pointwise attention로 수정하고, PAN의 shortcut connection을 concatenation을 로 대체했다.
정리하면 제안하는 YOLOv4에서 사용한 방법들은 다음과 같다.

Experiments
Experiments 에서는 이제 이러한 방법들의 조합을 통해가장 좋은 성능을 찾아가는 과정을 나타낸다.
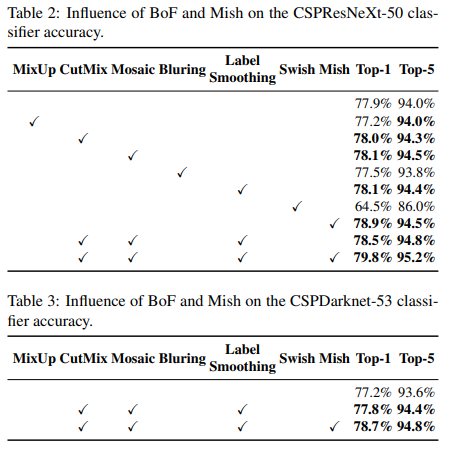
Influence of different features on Classifier training
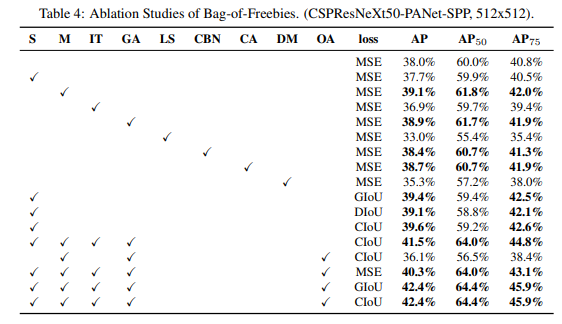
Influence of different features on Detector training

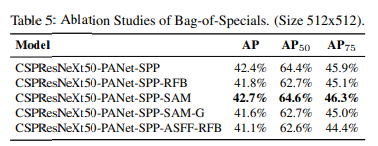
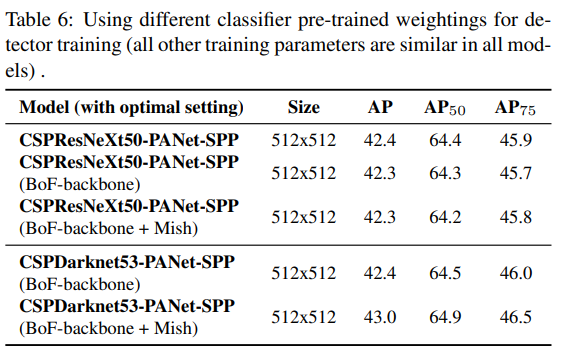
Influence of different backbones and pretrained weightings on Detector training
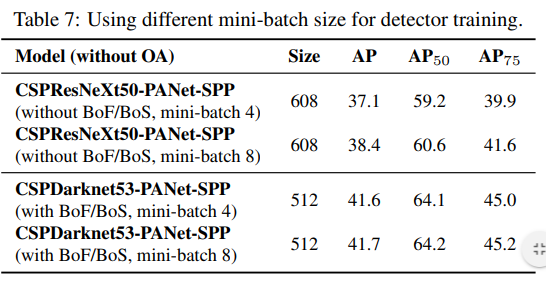
Influence of different mini-batch size on Detector training
다양한 방법의 조합들을 모두 실험했고 정리해서 나타냈다.
총평
novel method는 없지만 엄청난 실험결과가 바탕이된 분석적인 논문이다. 논문의 앞부분에서 백본을 어떻게 설정하는지 간단히 설명되어 있고 모델을 설계하는데 목표에 따라서 필요한것과 필요하지 않은것을 구별해서 선택적으로 모델을 설계하는 과정이 들어가서 해당 부분은 참고할만하다고 생각함. 그리고 일단 뭔가 새로운 논문을 쓰려면 이와 관련된 다양한 방법론들이 팔로우업되야한다는 걸 해당 논문을 읽으며 느낌(대충 뭐가 있는지는 알아야 쓸수있고 조합도 만들 수 있으니) 마지막으로 SAT 방법을 AF에 적용할 수 있을지 검토해볼 필요성이 있을것으로 생각된다.