이번에 소개드릴 논문은 NIPS 2017에 발표 되었던 Unsupervised Image-to-Image Translation Networks (UNIT) 입니다. 제안하는 network의 목적은 서로 다른 두 도메인의 unpaired한 영상, 즉 unsupervised 하게 각각 반대의 도메인 영상으로 변환하는 데에 있습니다.
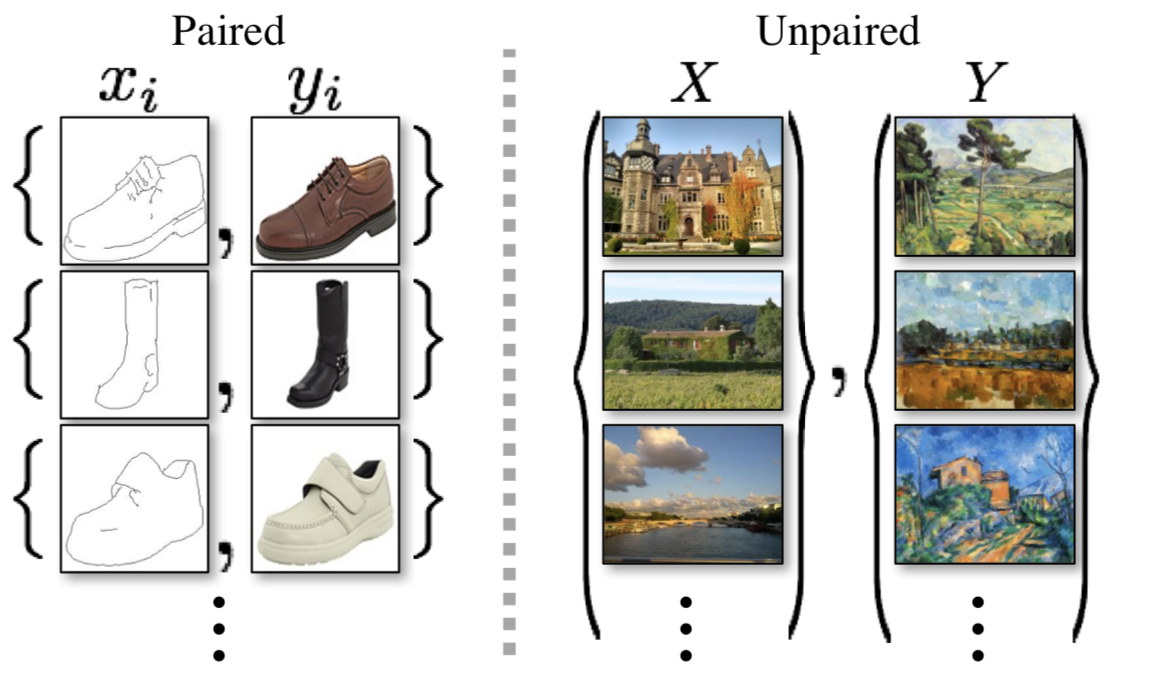
Unpaired 한 영상이란 다음과 같이 두 도메인 모두에서 일대일 매핑이 되지 않는 경우를 말합니다.
1.Network
1.1 VAEs-GANs
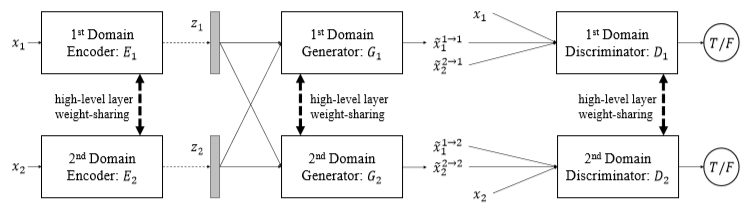
Unsupervised 하게 다른 도메인의 영상으로 바꿔주는 UNIT의 network는 전체적으로 VAE와 GAN이 결합한 구조 입니다. 그림에서 VAE는 {E, G}인 부분이며 GAN은 {G, D}인 부분으로 VAE와 GAN은 서로 Generator를 공유하고 있는 구조입니다. VAE의 Encoder에서 매핑된 latent space는 VAE 특성상 gaussian distribution 을 지니게 되는데 VAE와 GAN이 Generator를 공유하는 구조로 구성된 까닭에 GAN에 이러한 latent space가 input으로 들어가게 됩니다. 두 도메인의 unpaired한 input이 들어가기에 이와 같은 VAE-GAN 구조는 그림처럼 두 개로 구성이 됩니다.
1.2 Weight-sharing
본 저자는 Encoder에서 어느 정도의 layer를 거치고 난 후의 high-level feature가 두 도메인 상의 변환을 위해서는 유사해야한다고 생각을 하였고 이로 인해 Encoder의 뒷 부분 layer의 weight는 두 도메인이 서로 공유하도록 구성하였습니다. 마찬가지로 Generator의 경우에도 reconstruction이 충분히 진행되기전 explicit한 정보가 담겨 있는 high-level feature에도 이러한 이유로 weight를 서로 공유하도록 설계했습니다. 또한 Discriminator의 high-level feature에도 마찬가지 이유로 weight를 공유하게 구성했습니다. 그리고 각각의 domain에서의 latent space 들은 반대의 decoder로 들어가게 해 image-to-image translation을 위해 쓰이게 됩니다. 이로써 latent space에서 서로 반대의 도메인의 Decoder(=Generator)로 들어가는 것을 image translation stream이라 하고 해당 도메인의 Decoder로 들어가는 것을 image reconstruction stream이라 합니다.
1.3 Training
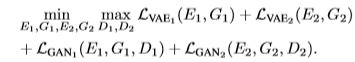
전체적으로 다음 조건에 만족하도록 학습이 진행됩니다. 기존 GAN이 학습하는 방식과 유사하게 Discriminator는 Loss를 크게 만들도록, Encoder와 Generator는 Discriminator를 속여 Loss를 작게 만들도록 학습하게 됩니다.
- VAE Loss
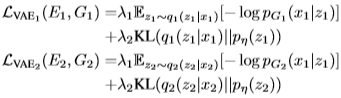
VAE의 Loss는 hyper parameter인 \lambda_{1}, \lambda_{2} 가 두 개의 term의 weight를 조정하게 됩니다. 이 두 개의 term 중 하나는 KL divergence term을 사용하게 됩니다. KL divergence term은 latent space의 이전분포에 대한 현재 분포의 편차에 제약을 두어 정규화하는 효과를 주게 됩니다. 나머지 하나의 term은 negative log-likelihood term을 사용하게 되는데 likelihood인 p_{G_{1}}( x_{1} | z_{1} ) 는 gaussian 을 이용한 것이어서 \frac{1}{2}exp( \frac{-|| x_{1}- G_{1}(z_{1})||^{2}}{2}) 와 같이 나타낼 수 있기에 negative log-likelihood term을 minimize 시키는 것은 input image와 reconstructed image 간의 Euclidean distance를 minimize 시키는 것이라 볼 수 있습니다.
- GAN Loss
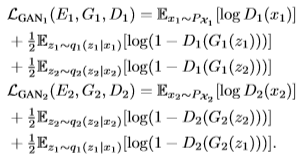
GAN의 Loss는 기존의 GAN의 Discriminator Loss는 같으나 Generator에 대한 Loss term은 두 가지 형태로 구성이 됩니다. q_{1}(z_{1}|x_{1}) 가 있는 term은 reconstruction에 대한 Generator Loss term이며 q_{2}(z_{2}|x_{2}) 가 있는 term은 translation에 대한 Generator Loss term 입니다.
2. Result
- Kaist multispectral pedestrian detection benchmark

- CelebFaces

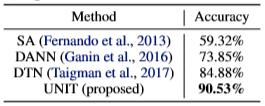
그리고 UNIT을 통해 Unsupervised Domain Adaptation도 가능하며 SVHN 데이터를 MNIST로 adaptation 시킨 결과도 공개했습니다.