해당 논문은 보행자가 속하는 박스의 pixels의 scale에 따라 다른 경향성을 나타나는 feature를 사용해서 학습결과를 조금더 좋게 만들어 보자는 컨셉이다. 아래의 사진을 보면 육안으로 확인 가능하다.
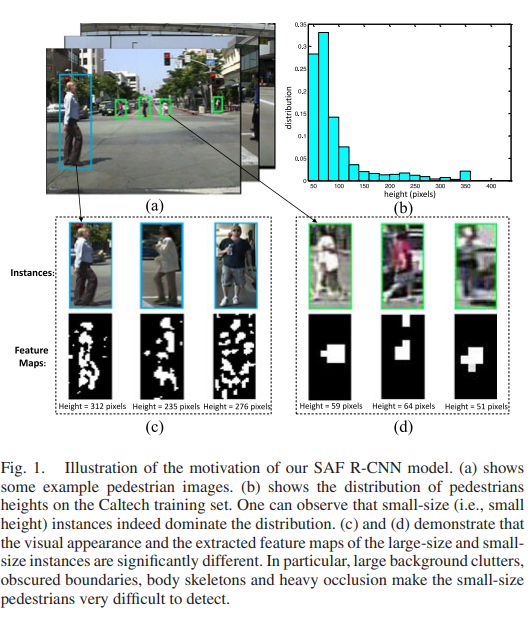
Main idea
기존 연구는 brute-force data augmentation을 통해 scale invariance 를 해결하는 방법과 single model에서 multi-scale filters를 사용하여 scale에 따른 문제를 해결하려고 한다. 하지만 해당 연구는 divide-and-conquer philosophy으로 접근하여 문제를 해결한다.
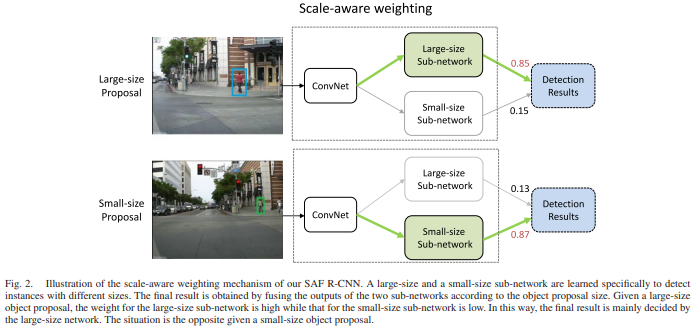
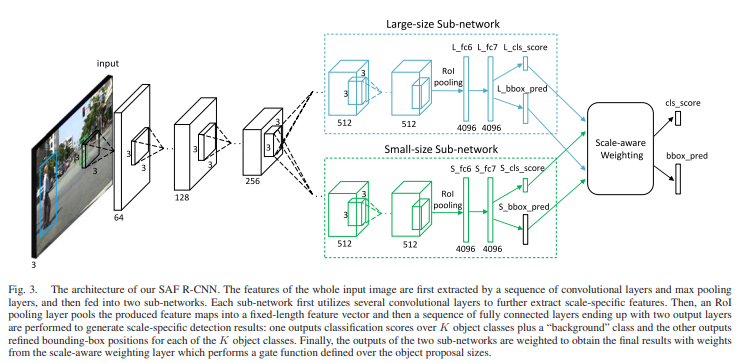
해당 연구는 proposal을 구하여 large-size proposal일 경우와 small-size proposal열 경우 두가지로 나눠 각각 스케일에 맞게 weight를 다르게 주어 학습을 진행 합니다.
Detail
- 기존의 Fast R-CNN의 방법으로 proposal을 구한다.
- 평군 h(bbox의 h)값보다 proposal의 h가 작을경우 large scale의 sub-network의 weight 값을 키우고 반대일 경우 small scale의 sub-networkdml weight 값을 키운다.
- cls는 log loss, loc는 smooth L1 loss를 사용하여 학습을 진행한다.
large weight
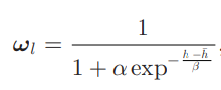
small weight
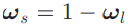
weight 식을 보면 알파와 베타가 있는데 이것은 learnable scaling coefficients를 스케일에 대한 가중치를 학습 한다. 해당 파라미터의 loss는 아래와 같다.
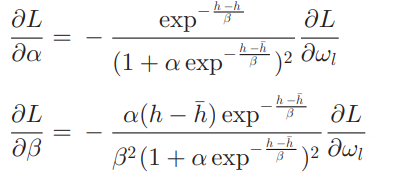
Net work
Optimization
위에서 구한 scale에 따른weight를 통해
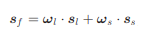
confidence score를 구하고
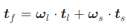
bounding-box regression을 구한다.
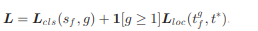
위에서 구한 값들로 log loss를 통해서 cls를 구하고 smooth loss를 통해서 loc를 구한다.