리뷰에 앞서 간단하게 해당 논문에 대해 소개하자면 large scale indoor dataset (InLoc)과 large scale indoor visual localization에 대해서도 제안을 했습니다.
이번 x-review로 InLoc을 결정한 이유는
1. CVPRW2019 Long Term Visual Localization, Indoor 부문에서 사용된 dataset으로 현재 작업 중인 indoor visual localization을 정량적 평가 하기 위해
2. Indoor Vsiaul localization의 파이프라인을 이해하기 위해
3. ‘Pedestrian Detection: The Elephant In The Room’에서 제안한대로 다양한 환경에서 촬영된 데이터 셋으로 추가적인 학습을 하여 보다 강인함을 얻기 위해. ex) 네이버 실내 데이터 셋 + InLoc
위 와 같으며, 해당 리뷰를 통해 캡스톤을 함께하는 동료들과 visual localization에 관심이 있는 동료들에게 도움이 되었으면 좋겠습니다.
Contribution
해당 논문이 기여한 바는 다음과 같습니다.
1. 실내 환경을 타겟으로 둔 새로운 large-scale visual localization 방법을 제시한다.
(1) Large-sclae 환경에서 scalability를 보장하는 후보 poses의 효율적인 검색
(2) Testurless indoor scenes를 계산하기 위해 Local feature보다 dense mathing을 이용한 pose estimation
(3) viewpoint, scene layout, occluders로 인한 큰 변화에 대처하기 위한 virtual view 합성에 의한 pose verification
2. 6-DOF 정보가 포한된 large-scale indoor dataset을 선보인다.
3. 이전 indoor visual localization 방법들에 비해 큰 성능 향상을 보이며 SOTA를 달성하였다.
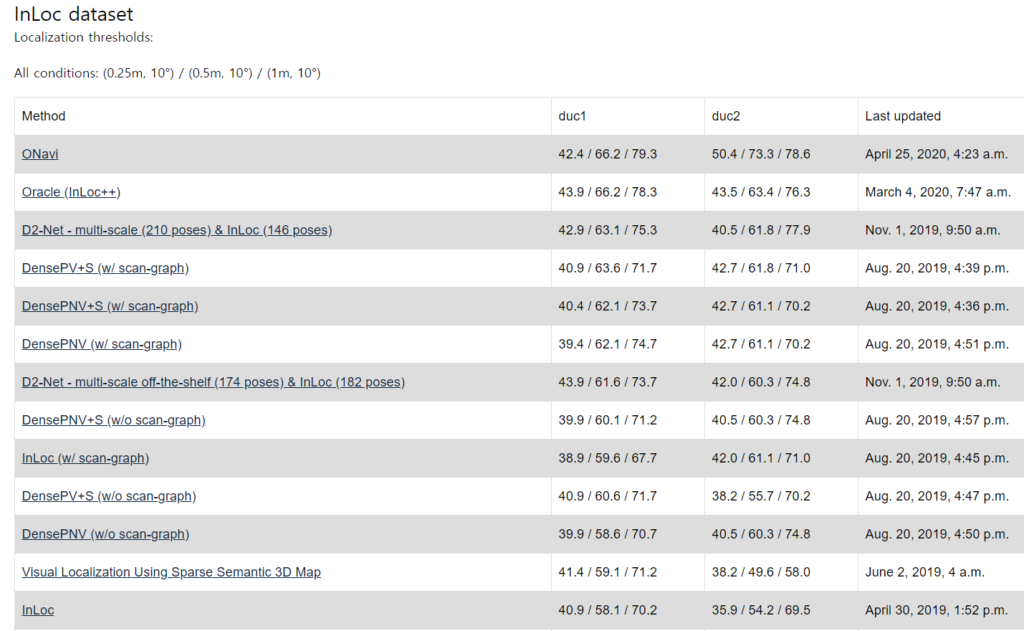
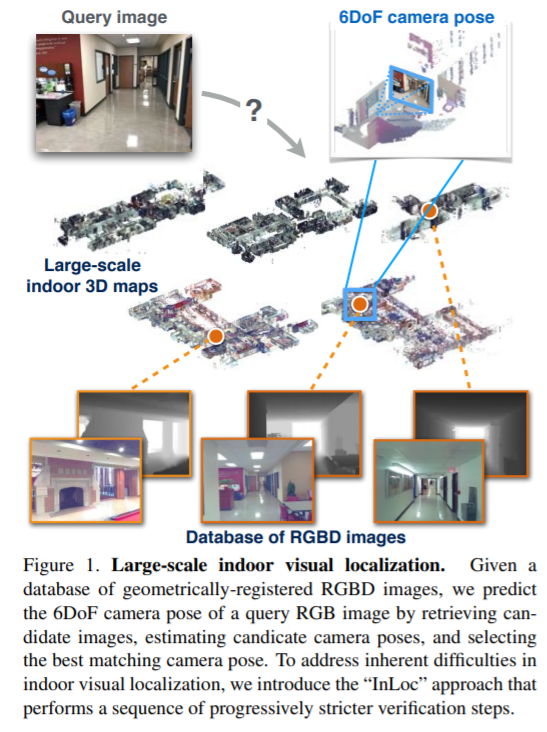
The InLoc dataset for visual localization

Database
- The Washington University in St. Louis’에서 두 건물, 5층의 복도에서 촬영하였다.
- Database는 Faro 3D scanner로 촬영하였다. area per scan: 23.5 ~ 185.8 m^2

- 각 영상들은 3D map의 global coordinate에 맞게 손수 검증된 6D camera pose를 포함하고 있다.
- 다섯 개의 scenes으로 구성 되어 있다. (DUC1, DUC2, CSE3, CSE4, CSE5)
- geometric 정보는 [1]에서 제안한 방법으로 구성함.
- 지나가는 행인, 가구의 위치 변동, 유사한 장면들을 포함하고 있다.
- Database는 9,970장의 RGBD 영상을 포함하고 있다.
Query image
- Query image는 hand-held devices인 iphone 7으로 촬영함.
- DUC1, DUC2에서 촬영을 진행하였다. database의 나머지 3층은 포함되지 않았으며, search time을 혼란시키는데 역할을 함.
- Query image는 각각 다른 시간 다른 날에 촬영되어 illumination, people, furniture를 포함하고 있다.
- 총 356 장의 영상을 가지고 있다.
- query image의 pose는 아래와 같은 파이프 라인을 통해 생성했습니다. (해당 정보를 Ground truth로 사용)
1. database img에서 가장 시각적으로 가장 유사한 영상들을 선택
2. 선택한 database img 와 query img간 affine covariant features, nearst-neighbor를 이용한 자동 매칭
3. query img의 camera pose를 계산하고 reprojection에 대해 수동적인 확인을 한다.
4. 매칭이 잘되지 않은 query 영상에 대해 수동 일치 후 pose 계산
5. 육안, 정량적인 검사
Indoor visual localization with dense matching and view synthesis
(1) Lack of spars local feature
벽, 천장, 복도 등 feature를 표현하기 힘든 곳에서 spare feature extraction method는 아주 적은 features를 얻게 됩니다. 이에 대한 해결 방안으로 mulit-scale dense CNN feature를 이용하여 해결했습니다. 모델은 outdoor를 통해 pre-trained model을 사용했습니다. CNN feature는 image description과 matching에 사용하였습니다.
(2) Large image change
실내 환경에서는 가구의 움직임, 사람등 이동이 가능한 물체들이 많다. 가장 유사한 영상을 visual retrieval로 푼다면 이동이 가능한 물체들로 인해 실제로는 같은 영상이지만, 시각적으로 다른 모습을 보여줌으로 문제를 해결하기 어려워진다. 이에 대한 해결 방안으로 가능한 한 많은 양의 positive evience를 얻기 위해 dense feature(CNN)를 이용합니다. pose estimation 단계에서는 coarse-to-fine feature matching을 이용합니다. 이어서 기하학적 검증과 camera pose estimation을 P3P-RANSC[2]을 이용하여 수행합니다.
(3) Self-similarity
실내 환경에서는 반복적이고 유사한 물체(self-similar)(ex. 복도, 방, 창문, 타일, 의자, 문 등)들이 존재합니다. 기존의 방식들은 positive evidence의 갯수를 세고 즉 inliers인 feature matching이 얼마나 많은지를 계산하여 두 영상을 matching 시킵니다. 위와 같은 방식을 사용하면 self-similar한 물체에서 positive evidence를 얻어 잘못된 매칭을 할 문제가 발생합니다. 해당 논문에서는 이 문제를 극복하고자 negative evidence(영상의 어떤 부분이 일치하지 않는지, 동일한 위치의 두 시점을 가져올지 결정 여부)의 갯 수를 고려하여 방지합니다. 해당 목적을 달성하기 위해서 3D 모델(View synthesis)을 이용하여 query img의 pose estimate verifivcation을 수행합니다. 즉 query img와 3D model(database)의 가상 뷰와 비교합니다. 새로운 접근 방식은 RGBD database의 높은 품질을 이용하여 전체 query img에 걸쳐 일치하는 픽셀과 비매칭 픽셀을 세어 positive, negative evidence를 모두 제공합니다.
query img가 주어졌을 때, InLoc의 파이프라인을 정리하자면 아래와 같습니다.
- database로 부터 N 개의 best matching img를 얻습니다.
- N개의 retrieved imgs에 포함되어 있는 6D 정보를 이용하여 query의 pose를 계산합니다.
- View synthesis에 의한 verification에 근거하여 계산된 포즈의 순위를 다시 정합니다.
Candidate pose retrieval
반복적이고 이동 가능한 요소들이 많은 indoor 환경에서 dense한 CNN을 이용한 해결책을 제안 했습니다. 해당 논문에서는 NetVLAD를 이용했습니다. NetVLAD를 이용하여 dense feature( nomalized L2 )를 descriptor로써 사용합니다. query, database img들에 적용하며, database로부터 N best matching img의 pose들을 candidate pose로 선택합니다.
Pose estimation using dense matching
VGG16에서 추출된 feature map을 이용하여 feature matching과 후보 영상들을 검증과 re-ranking을 수행합니다. conv5에서 기하학적으로 일치하는지 찾고, conv3에서 추가적인 matching을 수행합니다. P3P-RANSAC을 이용하여 query img와 database img의 pixel-by-pixel 대응 관계를 구하여 matching 시키고, camera pose를 추정합니다.
Pose verification with view synthesis
해당 세션에서는 무엇이 일치하고 일치하지 않는지 결정하기 위해 positive/negative envidnece를 모두 수집합니다. database를 통해 구축된 3D map과 query img간 어느 영역에서 일관성이 없는지 있는지를 픽셀 방식으로 셀 수 있게 합니다. 해당 방법에서는 조도 변화나 작은 미정렬에 대해 불변을 얻기 위해 DenseRootSIFT를 이용하여 영상 유사성을 평가합니다. 해당 평가에서는 추출된 descriptor의 중앙값으로 계산 됩니다.
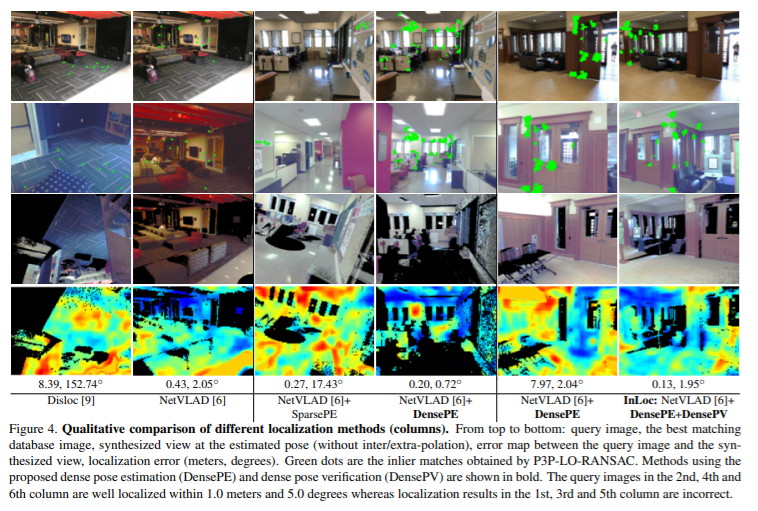
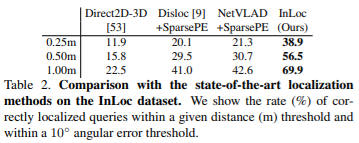
Experiments
해당 논문에서는 image retreival step에서는 pitts30k[3]을 이용하여 pre-trian된 NetVLAD을 사용했으며, cluster는 4096을 사용했다. NetVLAD를 통해 100개의 후보 database 영상을 추려낸다. pose estimation step에서는 NetVLAD의 backborn network VGG16의 conv5를 이용하여 매칭시키고, conv3를 통해 보다 더 촘촘한 일치점을 찾는다. 찾은 매칭점을 토대로 RANSAC을 통해 Homography를 얻고 100개의 후보군 중 top-10 database images를 얻는다. 얻은 top-10 영상의 pose들을 P3P-LO-RANSAC[4]을 이용하여 추정한다. 마지막 pose verification step에서는 color 3D point을 렌더링하여 synthesized viewsfmf 얻는다. query 영상과 유사성을 측정하는 점수와 추정된 pose를 통해 얻은 영상을 계산하기 위해 RootSIFT와 VLFeat의 denseSIFT를 이용한다. top-10 영상 중 가장 높은 점수를 받은 정보를 localize한다.
Reference
[1] E. Wijmans and Y. Furukawa. Exploitiong 2D floorplan for building-scale panorama RGBD alignment. In Porc. CVPR, 2017
[2] M. A. Fischler and R. C. Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Comm. ACM, 24(6):381– 395, 1981.
[3] R. Arandjelovic, P. Gronat, A. Torii, T. Pajdla, and J. Sivic. ´ NetVLAD: CNN architecture for weakly supervised place recognition. In Proc. CVPR, 2016
[4] M. A. Fischler and R. C. Bolles. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography. Comm. ACM, 24(6):381– 395, 1981
처음에 이 논문을 읽었을 때, NetVLAD와 CNN을 사용하여 feature 표현을 한다고하여 end-to-end 방식일거라고 생각을 했는데 그렇지 아닌 부분에 놀랐습니다. 어느새인가 deep-learning이라는 색안경에 내가 보는 연구들은 학습이 필요해, 라는 고정 관념이 생긴거 같습니다.
해당 논문에 대해 이해한대로 정리하자면, 1. 쿼리와 데이터베이스 영상들을 NetVLAD를 이용하여 global descriptor로 표현하고 이를 NN을 통해 N 개의 베스트 영상들을 선별합니다. 2. 선별된 영상들을 NetVLAD의 backborn network인 VGG16의 conv3, 5의 feature map을 dense한 local descriptor로 사용하여, N 개의 선별된 영상들과 query 영상간 호모그래피를 구해 top-k를 구합니다. 구한 top-k로 부터 P3P-RANSAC을 이용하여 매칭시키고 6D pose를 추정합니다.(DensePE) 3. 해당 매칭이 맞는 지 검증하기 위해서 추정된 6D pose와 가까운 pose를 가진 3D map의 영상간 유사성을 조도와 스케일에 불변인 DenseRootSIFT를 이용하여 유사성 점수를 매기고 가장 높은 점수를 받은 정보를 출력합니다.(DensePV)