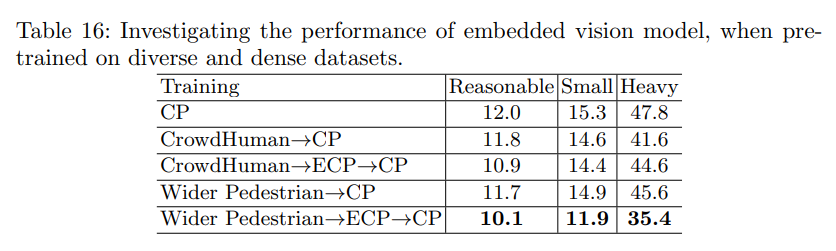
실험부분에 대해서는 도표에 대한 설명이 주를 이루고있어 생략하고 있습니다. 본 논문을 읽으면서 도표를 이해하시는것을 추천하며 주말동안 도표에 따른 설명부분도 추가하겠습니다.
https://arxiv.org/abs/2003.08799
Abstract
보행자은 매우 중요한 기술이다. 그래서 많은 사람들이 연구를 했고, 보행자 인식에 대해서 높은 성능을 보이고 있다. 하지만 이전에 제안된 많은 보행자인식 알고리즘이 높은 성능을 나타내고 있음에도 아직까지 해결하지 못한 문제가 있는데, 본적 없는 데이터에도 잘 작동하도록 모델의 일반화가 잘 이뤄지지 않는다는 점이다. 논문에서는 이러한 점들을 포괄적으로 연구하였고, 기존 보행자 인식에서 SOTA라고 불린 알고리즘들이 다른 데이터셋에 대해서는 poor하다는것을 발견했다. 이러한 현상이 나타나는 이유가 2가지라고 논문은 설명하고 있는데, 첫번째는 기존 유명한 데이터셋에서 SOTA라고 알려진 모델들은 그 특정 데이터셋에 대해서만 오버피팅 되었다는 것이고, 두번째는 학습을 위한 source가 대부분 보행자는 dense하지 않고, 시나리오가 다양하지 않다는 점이다. 논문에서는 cross-dataset evaluation을 수행하였을때,다른 SOTA 알고리즘과 비교해 general purpose object detector가 더 잘 작동함을 이야기한다. 또한 이 모델이 웹 크롤링을 통해 얻은 dense하고 다양한 데이터셋이 보행자 인식을 위한 효과적인 프리트레이닝의 소스가 됨을 이야기한다.
Introduction
보행자 인식은 학계와 산업 모두에서 가장 활발히 연구가 이뤄지고 있는 task이다. 다른 어떤 컴퓨터비전 알고리즘들보다 가장 중요한 역할을 수행하기 때문이다. 보행자 인식은 매우 도전적인 문제인데 왜냐하면 보행자 형태에는 스케일, 자세, 옷, 모션 블러, 조명, 가려짐, 둘러싸임, 등 많은 변형이 있기 때문이다. 특히 가려짐과 작은 스케일은 가장 도전적이고 현재 보행자 인식 모델들에게 가장 걸림돌이 되는 제약조건이다.
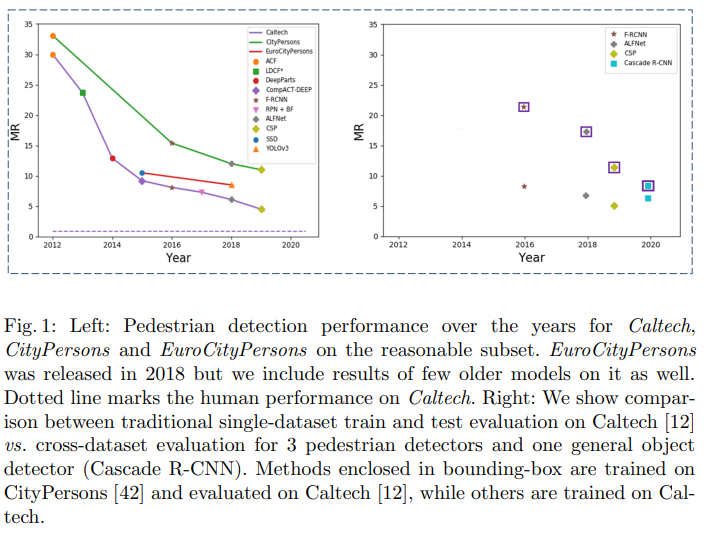
위의 그림에서 왼쪽은 최근 보행자 인식에 주요한 세가지의 결과를 나타낸다. 딥러닝은 최근 보행자 검출의 극적인 성능 향상을 가져왔다. 하지만 현재의 보행자 인식 방법들은 특정 데이터셋에만 오버피팅된것을 위의 그림 오른쪽을 통해 확인할 수 있다. 이건 최근 제안되는 모델들이 타겟과 다른 데이터셋에는 일반화되지 못했다는 것을 나타낸다. 이러한 이유로는 2가지를 생각할 수 있는데, 첫번째는 전통적으로 하나의 데이터셋을 학습하고 평가하는 파이프라인에서는 최근 SOTA 보행자 검출 모델이 타겟 데이터에 딱 맞춰졌고 전체적 디자인이 타겟 데이터셋에 맞춘 biasness를 포함하고 있어 일반화(generalization)를 감소시킨다는 것이다. 두번째는 일반적으로 학습 데이터에도 dense한 보행자가 없고 다양한 시나리오를 가지고 있지 않다는 것이다. 현재 SOTA의 보행자 검출 모델들은 딥러닝 기반이기 때문에 데이터의 양과 질에 강하게 의존한다. 이는 이미지 분류문제에서도 증명됐듯이 성능향상을 위해서는 최소 billions이상의 샘플이 필요하다. 보행자 인식 연구 커뮤니티는 최근 몇년간 크고 더 도전적인 데이터셋들을 publish하고 있다. 이로 최근 데이터셋이 몇배 증가했음에도 불가하고 , 아직까지 데이터는 하나의 bottleneck이 되고 있다. 요즘 모든 자율주행과 연관된 데이터셋은 최소 3개의의 제약조건이 있다, 1. unique한 보행자의 수가 제한됐고, 2. 보행자 밀집도가 낮고 도전적인 가려짐 샘플이 상대적으로 희귀하며, 3. 유튜브와 페이스북 같은 곳에서 다양한 소스를 가져오는 대신 작은 팀들에 의해 보행자셋이 촬영된 데이터셋이다보니 다양성이 제한된다는 것이다. 지난 몇년동안 두개의 크고 다양한 데이터셋이 웹 크롤링을 통해 수집됐다.(CrowdHuman 데이터셋과 Wider Pedestrian) 이 데이터셋은 위의 제약 사항을 다뤘지만 a much broader 도메인으로 인해 자율주행 시나리오를 커버하기에는 충분하지 않았다. 그럼에도 이 데이터셋들은 아직까지 보행자 검출 모델의 일반화와 강인성을 위해 가치있으며, 자율주행 시나리오를 위해서는 유익하다. 이 논문은 크고 다양한 데이터가 주어진 일반적인 object detector와 비교해 존재하는 보행자 검출 방법들이 fare poorly함을 나타냈고, 잘 학습된 SOTA 일반 검출기가(보행자 데이터셋에 대한 어떠한 적용 없이도) 보행자 인식을 위해 특별히 변형된 방법들의 성능을 능가한다는 것을 증명했다. (그림 1 오른쪽을 보면됨) 또한 논문에서는 자율주행에서 더 좋은 보행자 인식 성능을 위해 일반 보행자 데이터셋을 더 잘 이용하는 학습 파이프라인을 제안했는데, 모델을 (타겟도메인으로부터 멀지만) largest datasets으로 학습하고 (타겟도메인과는 가깝지만)smallest dataset을 점진적으로 fine tuning 할때 크게 성능을 향상됨을 있음을 보였다. (Caltech, CityPerson, EuroCityPerson 데이터셋에서 MR기준으로) 이러한 성능향상은 논문에서 제시하는 cascade R-CNN 과 MobileNet뿐만 아니라 모든 보행자 검출에도 적용될 수 있다.
Experiments
실험세팅
데이터셋 Caltech, CityPersons, EuroCity Persons, CrowdHuman, Wider Pedestrian
평가방법 FPPI, MR^-2(=[10^-2,10^0]) 이며 Reasonable,Small,Heavy,Heavy*4,All로 나눠 평가진행
베이스라인 R-CNN family의 확장판인 Cascade R-CNN 사용 백본네트워크는 HRNet 사용
Benchmarking
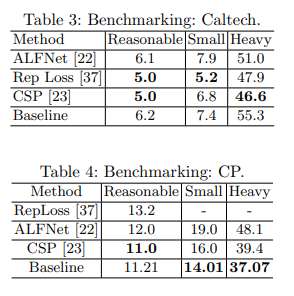
Generalization Capabilities
Cross Dataset Evaluation of Existing State-of-the-Art
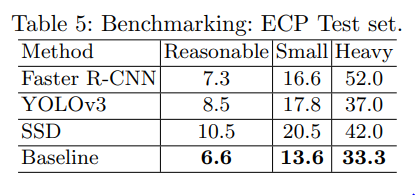
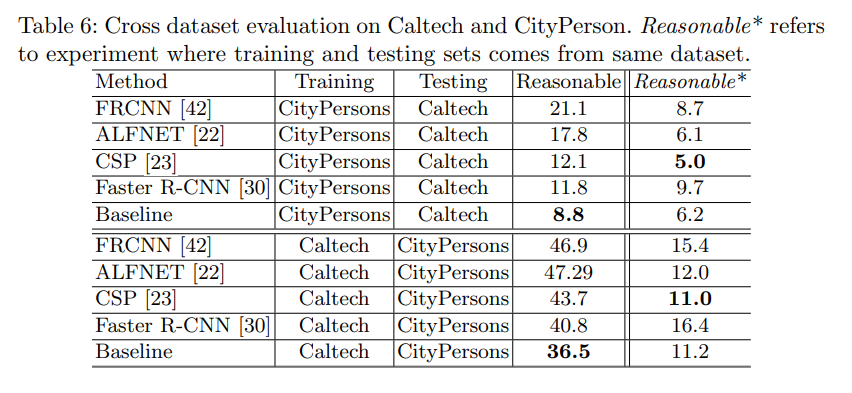
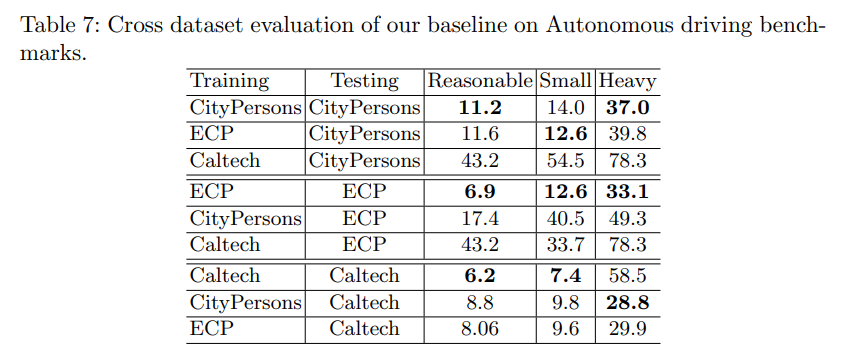
Pre-Training on Autonomous Driving Datasets
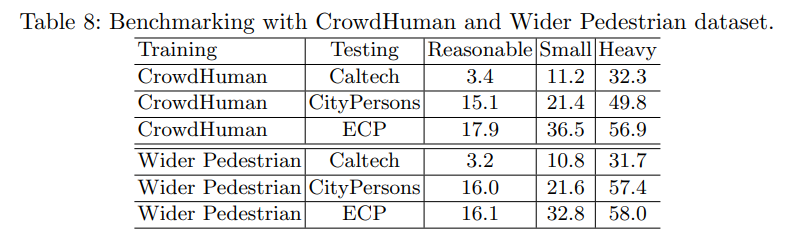
Pre-Training on Diverse Pedestrian Datasets
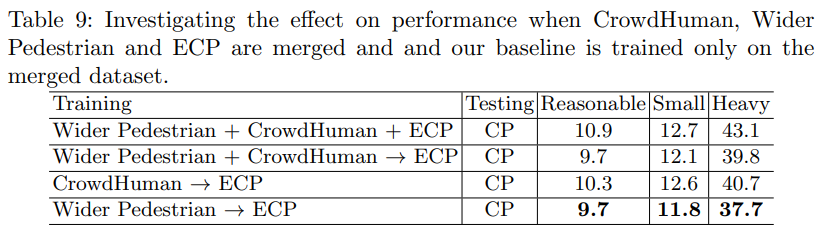
Discussion and Analysis
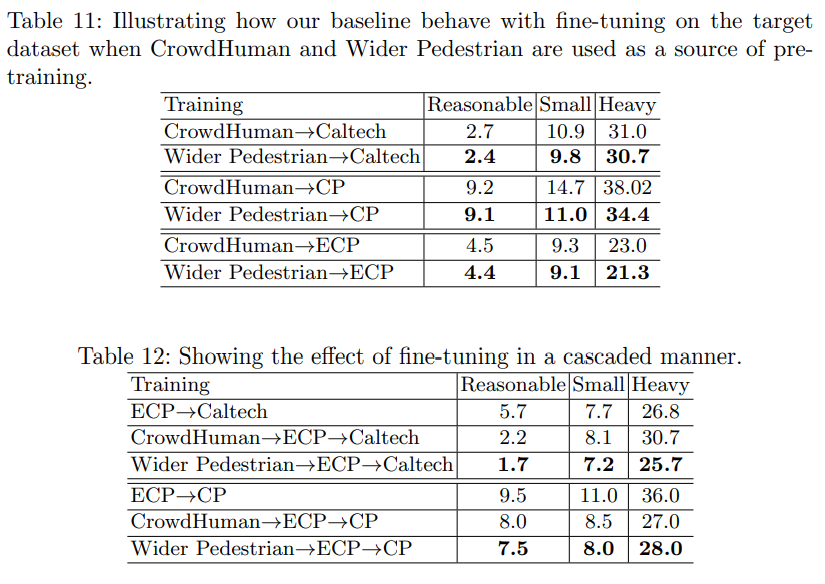
Effect of Fine-tuning on Target Data
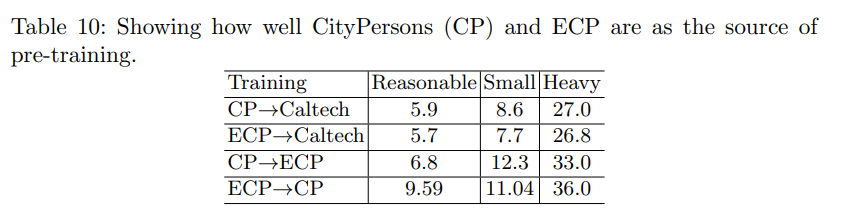
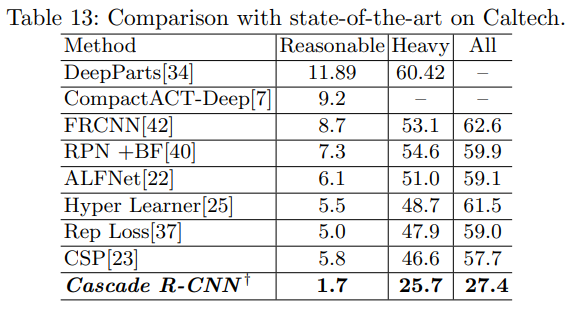
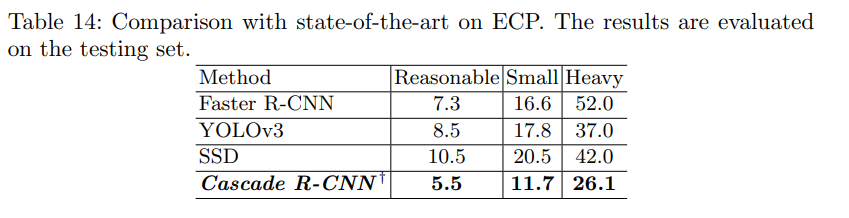
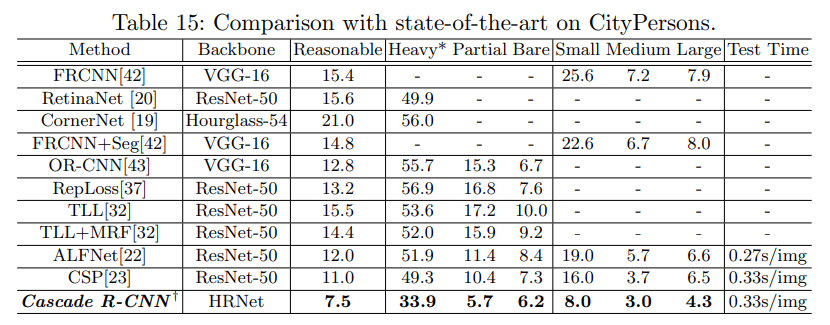
Comparison with Current State-of-the-Art
Application Oriented Models
Conclusions
논문에서는 SOTA 보행자 검출 알고리즘들의 실제환경에서의 성능을 보편적인 cross datasets evaluation을 통해 평가했다. 그리고 SOTA 알고리즘은 몇몇 벤치마크에 대해서 크게 성능향상을 이뤄냈지만 약간의 도메인 변화만 있어도 poorly하게 작동한다는 결론을 도출했다. 이는 현재 SOTA모델이 타겟 데이터셋에 오버피팅 됐기 때문인데, 전체적으로 타겟데이터셋에 bianess를 포함하도록 디자인됐고, 따라서 일반화되지 못한것이다. 대조적으로 일반 객체검츨은 더 강인하고 새로운 데이터셋에 대해서 잘 일반화 되어있다.
게다가 최근 유명한 자율주행 벤치마크는 군중밀집도와 더 중요한 다양성이 부족하다. 다양성 없이 데이터셋의 규모(양)만 늘린다면 성능 향상에도 제한적이다. 웹크롤링을 만들어진 보행자 데이터셋은 보행자의 robust representation 학습을 위한 더 풍부한 소스를 제공한다. 웹크롤을 통해 얻은 이미지는 이미지당 더 많은 사람이 있고, 더 많은 자세를 포함하며 다양한 크기와 가려진 정도를 제공하고 이러한 정보들은 모델이 더 일반화된 representations을 학습할 수 있게 한다.
논문에서는 다양성과 밀도 높은 데이터셋을 학습하고 후에 이를 자율주행 데이터셋에 대해서 파인튜닝하는것이 검출기의 일반화 능력을 향상시키고 가려짐에 더 강인하고 성능향상을 이룰 수 있다는 것을 설명하고 있다.