Abstract&Introduction
간단하게 요약을 하자면, 보행자 검출에서 크게 두 가지 방식으로 접근을 하는데, 하나는 object-detection, 다른 하나는 semantic segmentation 입니다. 각각은 모두 장단점이 존재하는데 다음과 같습니다.
- Object-Detection
- 장점 : 물체(보행자)가 어디에 위치하는지를 찾는 일(Localization)에 최적화.
- 단점 : 물체의 경계를 뚜렷하게 나누지 못하여 정보 손실이 조금 존재.
- Semantic-Segmentation
- 장점 : 픽셀 단위로 물체의 경계를 구분하여 class 검출
- 단점 : 같은 class끼리 구분하는게 힘듦.
위와 같이 두 방법은 장단점이 뚜렷합니다. 그렇기에 이 논문에서는 두 방법론을 같이 학습하면서 동시에 서로 학습할 때 참고할 수 있도록(joint supervision) framework를 infusion하는 방법론을 제시합니다.
Proposed method
이 논문은 기존 Faster-RCNN에서 Segmentation infusion layer를 적용하셨다고 보면 됩니다. 먼저 모델의 구조는 Faster-RCNN처럼 크게 Region Proposal Network(RPN)과 Binary Classification network(BCN)로 나뉘어져 있습니다. 그리고 이 두 개의 네트워크 모두 semantic segmentation infusion layer를 붙였고, 이를 통해 공유된 Feature map에서 semantic mask를 인코딩하여 더 강인한 검출 성능을 보였다고 합니다.
Region Proposal Network
먼저 이 논문에서 RPN은 Faster-RCNN에서의 세팅과 동일하게 사용했다고 합니다. 기존과 차이점이 있다면, 조금 더 보행자 검출 목적으로 맞추기 위해 aspect ratio를 0.41, 스케일 범위를 25~350 픽셀 사이로 고정했다고 합니다. 그 이유는 Caltech에서 제공한 보행자 통계치가 위와 같다고 해서 그렇습니다. RPN의 구조는 conv1-5에서 VGG-16을 backbone으로 사용하고, output layer는 box classification과 bounding box regression에 추가적으로 segmentation infusion layer를 붙였습니다.
RPN에서의 Loss는 다음과 같습니다.
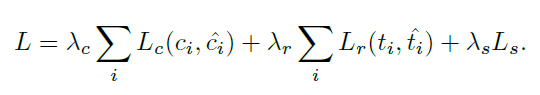
좌측은 classification loss, 중앙은 regression loss, 우측이 segmentation loss 입니다. 먼저 class부터 간단하게 살펴보면 softmax logistic loss이며 class의 라벨은 2가지(보행자=1, 배경=0)이고 IOU 0.5 이상일때를 보행자로 판단합니다.
regression loss의 경우는 박스의 좌표 값(x,y,w,h)에 대해 기존 Faster-RCNN처럼 robust loss function(smooth L1)을 적용하여 계산합니다. segmentation loss에 대해서는 뒤에서 설명하겠습니다.
Setting of RPN train
논문에서는 같은 사람에 대한 중복된 검출을 피하기 위해 NMS(threshold=0.5) 기법을 사용하였고, RPN을 학습 시킬 때 optimizer=SGD, lr=0.001, momentum= 0.9로 놓고 학습시켰습니다. 영상 한장당 proposal을 120개(보행자:배경=1:5)로 랜덤하게 샘플링하여 class 불균형을 완화시켰고, 그 외에 proposal들은 모두 무시해버렸습니다.
또한 이미지 넷으로 pretrained 된 VGG-16 model을 conv1-5로 초기화 하였고, 총 4개의 max-pooling layer가 존재합니다. 그리고 위에 loss 수식에서 classification과 segmentation에 대한 람다는 1, regression에 대한 람다는 5로 세팅하여 실험을 진행했습니다.
Binary Classification Network
BCN은 RPN에서 나온 proposal에서 보행자 검출을 수행하기 위한 목적으로 만들어졌습니다. 먼저 기존에 일반적인 물체 검출에서 BCN은 RPN과 conv1-5를 공유함으로써 후속 검출기로써의 역할을 맡아왔습니다. 하지만 보행자 검출에서는 그렇게 할 경우 좋지 못한 성능을 도출해냈습니다. 물론 연산을 공유하기 때문에 매우 바람직한 효율성을 보여주지만, 결국 fusion이 되었다는 것이므로 앞 단(RPN)에서 예측한 score와 유사한 score를 예측하는 모습을 보여주게 됩니다. 이미 앞단에서 구한 스코어기 때문에 뒷 단에서 다시 예측해봤자 그 스코어는 불필요한 스코어로 볼 수 있습니다. 그래서 이 논문에서는 더 나은 정확도를 위해 BCN을 RPN과 다시 분리하여 개별적인 네트워크로 만들었으며, 이를 통해 RPN에서는 잘 예측하지 못했던 sample(harder sample)들에 대해 전문적으로 예측할 수 있게 됩니다.
BCN의 Loss function은 다음과 같습니다.
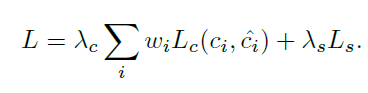
RPN과 마찬가지로 Lc는 classification loss, Ls는 segmentation loss를 나타냅니다. classification loss에서 살짝 다른 점이 있다면 w_{i} 가 추가 되었는데, 이 변수의 역할은 큰 보행자와 작은 보행자(영상에서 보이는 보행자 스케일)에 우선순위(가중치)를 주는 것으로 보면 됩니다. 우선 순위를 주는 이유는 다음과 같습니다.
- 큰 보행자는 전반적으로 카메라(자율주행차)와 가깝게 위치한다는 뜻이고 이는 가장 중요한 검출 대상입니다.
- 큰 보행자의 feature는 작은 보행자의 feature보다 더 유용합니다.
이러한 w_{i} 는 w_{i} = 1 + \frac{h_{i}}{h} 로 나타낼 수 있는데 h_{i}는 i번째 proposal의 height이며 h는 pre-computed된 mean height를 말합니다.
이 논문에서는 또한 labeling하는 방식에 대해서도 더 엄격하게 바꾸었는데, 첫째로는 보다 정확성을 높이기 위해, 0.7이상의 IOU값을 가진 proposal만을 보행자로, 그 외에는 배경으로 취급합니다. 둘째, BCN에서 구한 score를 앞에 RPN에서 구한 confidence score와 최소 한번 이상 합칩니다. 저자는 각각의 네트워크(RPN과 BCN)들이 융합되어야만, 각 네트워크의 특징을 잘 나타낼 수 있을 것이라 믿었습니다. 그래서 feature level 속 softmax를 하기 전에 score를 합치게 되는데, RPN의 class score와 BCN의 class score는 아래와 같은 softmax function을 통해 계산되어 집니다.
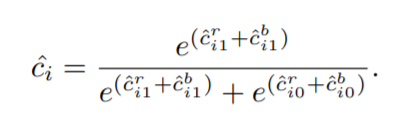
Simultaneous Detection & Segmentation – Segmentation Infusion Layer
그렇다면 Detection과 Segmentation을 동시에 하기 위해서 Segmentation gt를
따로 구해야하는 걸까요? 그렇게 하기엔 비용적 측면에서 문제가 생깁니다. 저자가 해결한 방식은 바로 box를 down sampling하여 segmentation mask처럼 사용하자 였습니다. 그 이유는 바로 아래 그림에서 볼 수 있는데 segmentation을 다운샘플링한 모습과 box를 다운샘플링한 모습이 서로 비슷하다는 것입니다. 논문에서는 infusion layer를 conv5에 붙였기 때문에, box기반 어노테이션과 segmentation 기반 어노테이션의 차이가 크게 줄어듭니다.
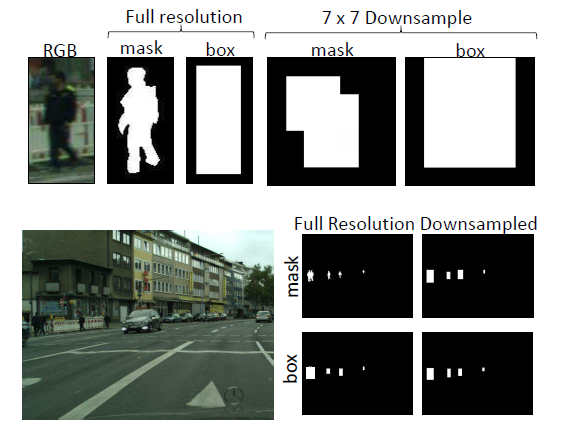
위에 그림에 대해서 추가적인 설명을 하자면, Caltech 데이터 셋에서 68%의 보행자 height는 80픽셀 보다 작습니다. 이는 RPN의 conv5에서 3 x 5 픽셀과 일치합니다. 또한 BCN의 proposal도 conv5에서 7 x 7로 pooling 됩니다. 그 덕분에 박스와 segmentation annotation의 차이가 별로 없게끔 됩니다.
자 그러면 이제 segmentation mask를 down sampling한 박스로 대체하였고 이를 feature map과 직접적으로 통합해서 나온 영상은 아래와 같습니다.
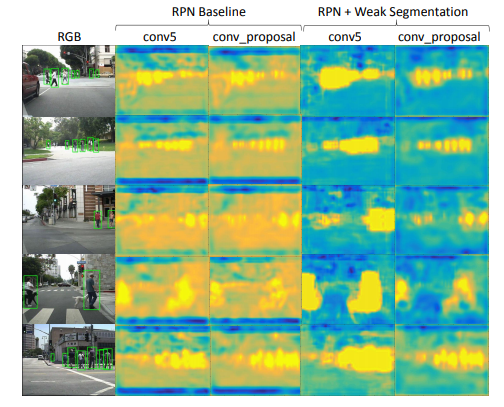
네트워크가 깊으면 깊을수록 더 정확한 segmentation을 얻을 수 있지만, 공유된 레이어로부터 잘 추측하지 못하여 전반적인 보행자 검출 능력이 감소하기도 합니다. 그래서 논문에서는 VGG backbone을 RPN과 BCN에 각각 한개씩 넣어서 네트워크가 Deep 해지는 것을 방지했습니다.
위에서 RPN과 BCN의 loss를 설명할 때 다루지 않았던 L_{s}에 대해 설명을 하자면, 이 segmentation loss는 밑에 식과 같이, 두 가지 class(pedestrian vs background)에 대한 softmax logistic loss를 뜻합니다.
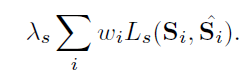
논문에서는 유명 보행자 데이터셋(Caltech 또는 KITTI 등)의 bounding box annotation을 가지고 weak segmentation ground truth mask 형식으로 바꾸었습니다. 이때 각각의 mask S는 보행자면 1, background이면 0이라는 라벨링을 부여받아 형성됩니다.
Benefits over Detection
Segmentation Infusion Layer가 Detection에 어떤 장점이 있는지에 대해 마지막으로 정리하고 글을 마치려고 합니다.
먼저 Segmentation supervision over detection의 첫번째 장점은 간단함입니다. Detection에서, anchor selection이나 IOU threshold, NMS 등의 하이퍼파라미터 설정은 필수적입니다. 만약 anchor scale이 매우 빈약하거나 IoU threshold가 너무 높으면 ground truth가 low supervision을 놓치거나 잡을 수 있습니다.
이와 반대로 semantic segmentation은 보행자의 형태나 occlusion 수준이 선택한 anchor들과 얼마나 잘 매칭되는지를 통해 모든 ground truths를 다룹니다.이론상으로, semantic segmentation을 합치는 것은 하이퍼 파리미터에 대한 conv1-5의 sensitivity를 줄이는데 도움이 됩니다.
마지막으로 segmentation supervision은 BCN에게 매우 효과적인데, 만약 보행자가 존재하는 경우 BCN에서 RPN에 의존하지 않고 스스로 보행자를 검출 할 수 있는 것 같습니다.