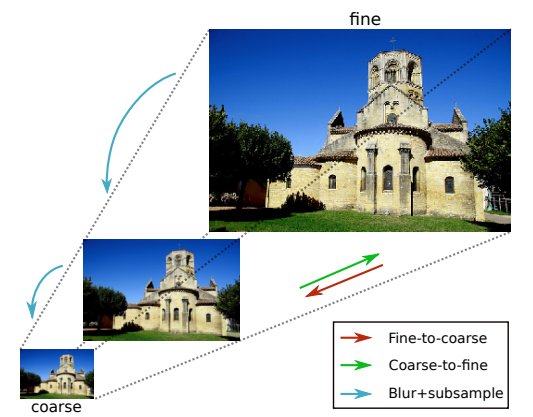
생물학적 vision에서는 보통 물체를 인식할 때 Coarse-to-fine방식으로 진행됩니다. 이와 반대로 CNN 방법들은 보통 Fine-to- coarse 방식(=BottomUp)으로 물체를 인식합니다.
이 논문은 생물학적으로 볼때와 같이 Coarse-to-fine 방식(=TopDown)으로 집중하게 하여, 점진적인 visual attention 효과를 확인하게 합니다.
https://github.com/giannislelekas/topdown
contributions:
(i) 새로운 top-down 방식
(ii) top-down방식과 bottom-up 방식의 비교
(iii)제안하는 방식이 특정 attack에 강인함
pointwise attack
Blurring attack
spatial attack
(iv)이전방식(bottom-up)에 비해 설명가능성의 향상

장면의 요지(gist)를 먼저 확인한 후, 더 자세한 정보를 받는다는것은 attention mask를 추가한다는 관점에서 합리적이라 생각합니다.