
논문: Adversarial Validation Approach to Concept Drift Problem in Automated Machine Learning System
이번 논문은 AutoML을 훈련시킬 때 training dataset과 test dataset의 분포와 특징이 달라서 생기는 성능 저하 문제를 GAN의 아이디어를 활용하여 훈련할 특징을 선택하는 방법에 대한 논문입니다.
이 논문에서 활용한 데이터셋은 Uber의 MaLTA(Machine Learning based Targeting Automation) 시스템을 통해 Uber 사용자의 데이터를 활용하였습니다. 데이터셋의 출처에서 알 수 있듯이 본 논문의 발행은 Uber에서 하였으며, 연구의 책임자는 이정윤님으로 과거 Microsoft Research에서 근무하였으며, Kaggle과 KDD Cup에서 왕성한 활동을 하는 분입니다.
산업 현장에서는 우선 비즈니스를 위한 모델을 만들고, 새로운 데이터가 충분히 모여서 새로운 버전의 모델을 만드는 방법 또는 새로운 데이터를 획득하게 되면 기존 모델을 불러와 추가로 훈련시켜 모델을 업그레이드하는 과정을 거치게 됩니다. 첫 번째 방법의 경우 한 번 선정된 모델은 즉각적인 피드백이나 업데이트 없이 계속 사용하게 되므로 비즈니스 측면에서 변화하는 사용자의 요구를 빠르게 반영할 수 없습니다. 두 번째 방법의 경우도 새로 수집한 데이터의 분포와 특징이 다르다면 이전의 모델은 무의미 해지고, 새로운 데이터에 한정된 모델이 생성되게 됩니다.
본 논문에서는 그림1. 과 같이 새로운 데이터(Test)의 분포나 특징이 다른 경우 효과적인 모델 훈련 방법을 제시하고 있습니다. 핵심 아이디어는 생각외로 간단한데 GAN의 Discriminator가 Fake와 Real을 구분(각 확률이 50%) 하지 못하도록 훈련하는 것을 착안하여 Train과 Test 데이터셋을 구분할 수 있는 특징중 가장 큰 영향력을 주는 특징들을 소거하는 모델을 훈련합니다. 그림 2.는 논문의 방법을 직관적으로 보여주는 그림이므로 이해하는데 도움이 됩니다.
제시된 모델을 훈련하기 위해서 Propensity Score Matching (PSM) 방법을 적용하였는데, 두 데이터셋 사이의 차이와 각 분산을 활용하여 Standardized Mean Difference (SMD)를 계산하여 PSM 방법에 사용하게 됩니다. (자세한 수식의 경우 논문 섹션3의 수식 (1)을 참고해주세요.)
사용하는 데이터는 이미지가 아니고, numerical features와 categorical features로 구성되어 있는 데이터입니다. 본 데이터를 사용하여 adversarial validation with feature selection을 실행할 때 3가지 알고리즘을 비교하여 훈련시킵니다. ((1)Decision Trees, (2)Random Forests, (3)Gradient Boosted Decision Trees)
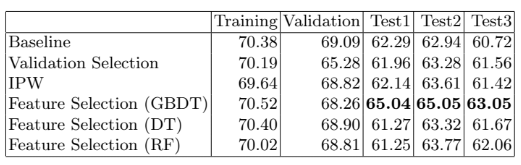
표1.의 경우 MaLTA 데이터셋을 사용하여 제시된 방법의 성능 향상을 보여주고 있습니다. 특히 Test 데이터셋의 결과는 Gradient Boosted Decision Trees 방법의 경우 baseline은 물론 제시된 다른 두가지 알고리즘보다 더 좋은 성능을 보여주고 있습니다.
본 논문은 GAN의 아이디어를 바탕으로 Data Engineering 을 자동으로 수행하는 방법을 제시하고 있습니다. 실제 통계를 다룰때 missing value, outlier 등을 처리해줘야 하는데 논문에서 제시된 adversarial validation feature selection을 활용할 경우 Train과 Test 데이터셋을 구분하는 뚜렷한 특징들을 제거하기 때문에 online learning을 잘 수행할 수 있어 산업현장의 비즈니스 모델에 활용하기 좋은 방법입니다.