
영상만으로 위치를 인식하는 place recognition에서 현재까지 활발히 활용되고 있는 NetVLAD입니다. 기존 VLAD 와 BoW, FV 등 영상을 대표적으로 표현할 수 있는 Global Descriptor를 생성하는 모델로 활용 하여 place recognition의 그당시 제일 높은 성능을 발휘 했습니다.
이 논문이 제안하는 특징들은 크게 세가지로 나올수 있습니다.
- 기존 descriptor 와 Cluster center 사이의 거리관계를 활용한 VLAD 를 CNN 에 맞게끔 설계하여, 영상에서 효율적으로 구별가능 한 descriptor를 생성한다
- 큰 규모의 panoramic images 를 포함한 데이터셋을 place recognition 을 위해서 모으고 제공한다고 한다. 이 데이터셋은 전세계에서 GPS값이 비슷한 곳들을 촬형했으나 , 두곳이 정확히 같은곳을 바라보는것은 확신할 수 없다고 한다. 또한 촬영된 시간 다르다고한다
- place recognition 의 학습 방식을 제안했다고 한다. 기존방식들보다 Database 와 query 영상의 촬영 포커스가 다르거나 빛의 강도, 종류에 강인하고 영상 비교에 영향을 끼치는 사람과 자동차를 무시하고 건물의 윤곽선이나 하늘의 형태 등을 학습한다고 한다.
- NetVLAD Pipeline
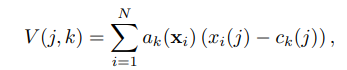
기존 VLAD는 식과같이 각 Local descriptor 와 가장 가까운 Cluster간의 거리를 1-D vector를 Global descriptor 로 나타낸다. 이렇게 가장 가까운 Cluster 만을 정보로 가지게 하지 않고 여러 cluster 와 거리관계를 가지도록 식 2 와 같이 0~1사이를 가지도록 ak를 설계했다.
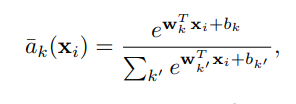
1,cluster가 CNN을 통해서 계산이 되고 그 output을 wx+b 가 만들어진다음 2,soft-max 속에 들어간 ak가 만들어지고 식 3을 통해 Global descriptor 를 구할 수 있다.
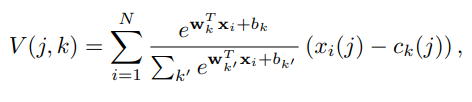
식 3 을 이용해 cluster를 학습 시키면 기존 VLAD는 Ck만 구했지만 NetVlAD는 총 세개의 파라미터를 학습 시킬 수 있어 적응성을 가진다.
기존 VLAD를 CNN에 맞게 설계했다는 점이 식1의 파라미터가 0 또는 1의 binary에서 식2처럼 0과 1사이의 값을 가지도록 변경한 것인가요? 논문에서 주장한 CNN에 맞게 설계한 점이 단순히 CNN 결과를 fully connected로 펼쳐놓은 것을 말하는 건가요? 만약 그렇다면 논문에서 제시하는 linear의 output feature 개수는 몇 개인가요?
0과 1 사이로 값을 가지도록 변경 된 것은, 기존 VLAD는 단순히 가장 가까운 cluster center 와의 거리를 계산 했다면 NetVLAD는 모든 cluster 와의 거리를 담아 좀 더 soft한 결과를 생성할 수 있다 합니다. CNN에 맞게 설계했다는 것은 학습을 통해서 Cluster 값 변경한 다는 점이 중요합니다. output feature 갯수는 Backbone 모델의 마지만 feature 의 dim X cluster 갯수 입니다.
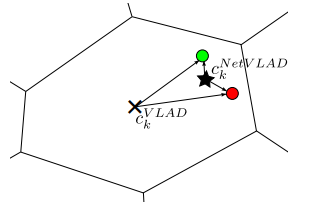
그림 2와 같이 최적의 cluster를 찾는다는 것은 식3의 V(j,k)을 학습하는 것일텐데 조금 더 구체적으로 설명해주실 수 있을까요?
NetVLAD를 사용해서 얻을 수 있는 장점이 어떤건가요? 정확도 성능이 향상되었는지 계산 과정의 리소스를 덜 사용하게 되었는지에 대해 알고 싶습니다.
일단은 CNN을 사용해서 학습을 하고 inference를 하기 때문에 inference 차원에서는 속도적인 장점이 생깁니다. 그리고 Handcraft기반의 방법론 중 그 당식 가장 좋았던 RootSIFT+VLAD 와 비교 했을때도 높은 성능을 기록했습니다. 이건 Cluster를 데이테에 맞게 추정 후 학습을 통해 더욱 정확한 값으로 수렴하므로 좋은 성능을 낸다고 할수 있을 것 같습니다.
감사합니다. 말씀주신 근거인 논문의 정량적 비교가 첨부되었다면 좋았을것 같습니다.