[github] https://github.com/liuwei16/CSP
컨셉은 간단하다.
이미지의 입력에서 보행자의 Center Point와 Scale을 찾아서 박스를 그리는 모델이다.
Anchor-free object detection의 방법이다.
Preliminary
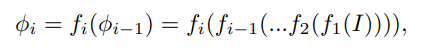
CNN기반 Object Detector는 Backbone network에 의존하는 편이다. 네트워크는 다른 resolution을 가지는 여러개의 피처맵을 만들어내며 이를 나타낸 수식은 위에 나타낸다. I를 이미지라고 한다면 i개의 피처맵(φ)은 f(.)에 의해서 생성된다. RPN에서는 마지막 N번째 피처맵을 사용해 detection을 수행한다. 따라서 detection을 위한 피처맵은 Φdet = {φN } 로 표현할 수 있다. SSD의 경우에는 detection을 위한 피처맵을 나타내면 Φdet = {φL, φL+1, …, φN } 이며 이때 1<L<N의 조건을 갖는다. 또 작은 스케일의 객체를 검출하기위해 shallower layers의 semantic information을 풍족하게 만들기위해 FPN과 DSSD는 다른 resolution의 피처맵들을 결합하기위해 lateral connection 을 활용한다. 결과적으로 Φdet = {φ ′ L , φ′ L+1, …, φ′ N } 이며 여기서 φ ′ i (i = L, L+1, …N) 는 φi(i = L, L + 1, …N)의 결합을 의미한다. anchor-based detectors에서의 또다른 키성분으로는 anchor boxes(default box)가 있다. 이를 B라고 할때 Φdet 와 B를 이용해 detection을 다음과 같이 공식화 할 수 있다.
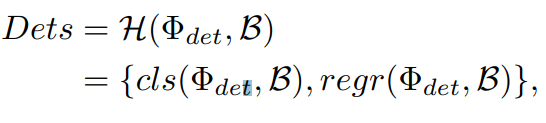
B는 보통 Φdet 에 따라 정의되며, H(.) 는 detection head를 나타낸다. 일반적으로 H(.) 는 두가지 성분을 포함하는데 cls(.)와 regr(.)이다. 이는 cls(.)은 classification을 위한 스코어를 예측하고, regr(.)은 스케일과 anchor 박스의 offset을 예측한다. 반면 anchor-free detector는 다음과 같은 수식으로 나타낼 수 있다.
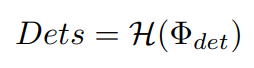
즉 anchor-free detector는 B, 즉 anchor box(default box)가 필요없다.
Overall architecture
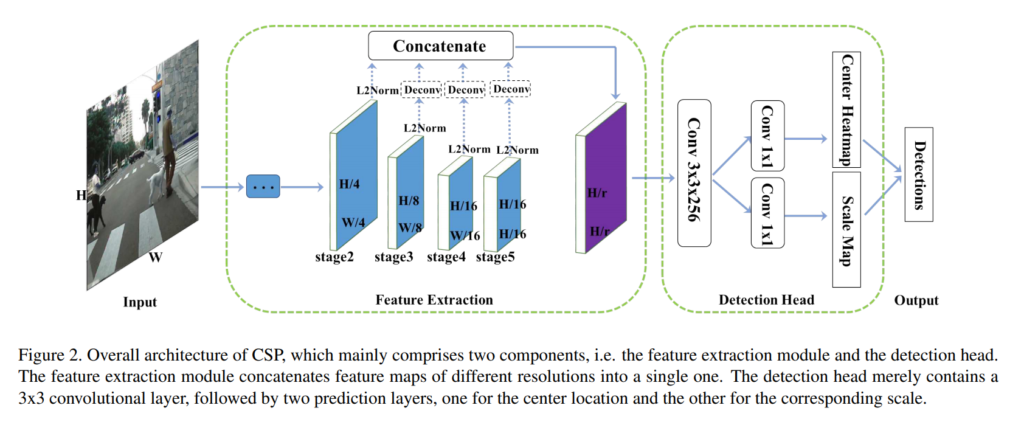
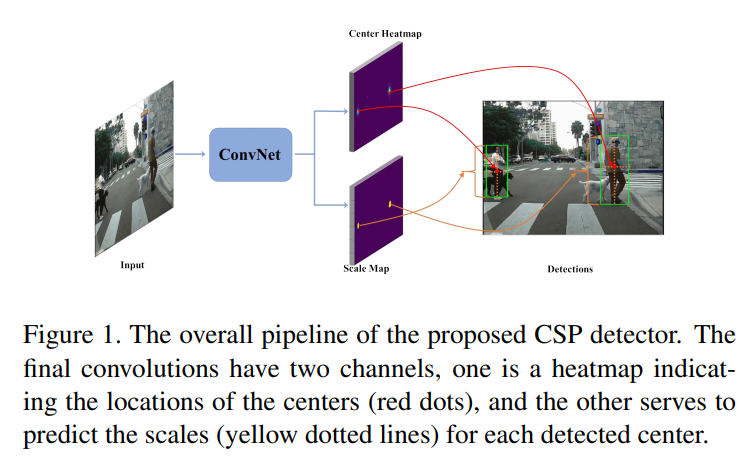
Feature Extraction
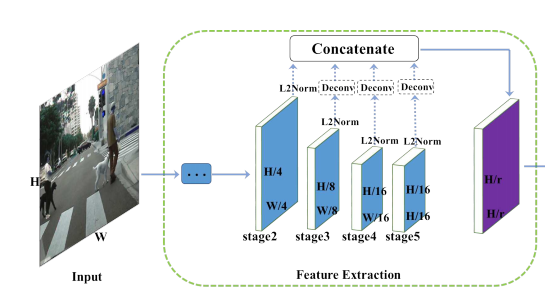
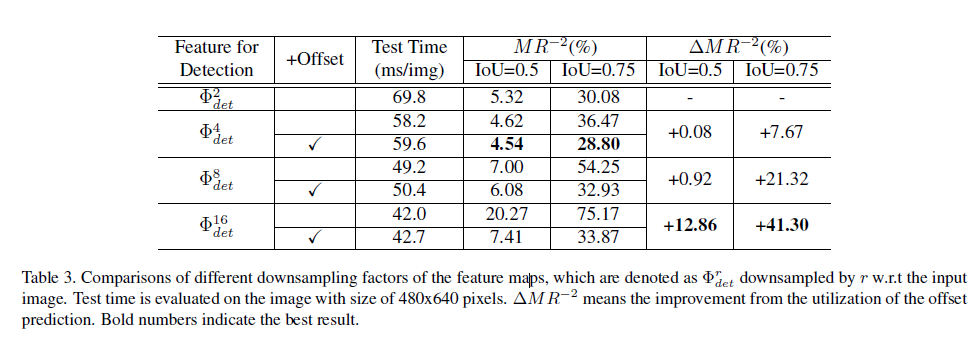
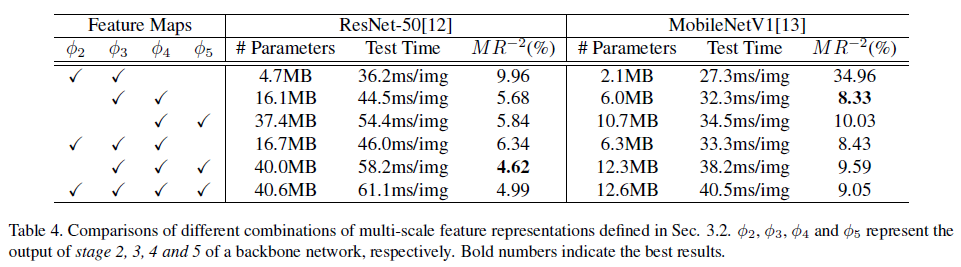
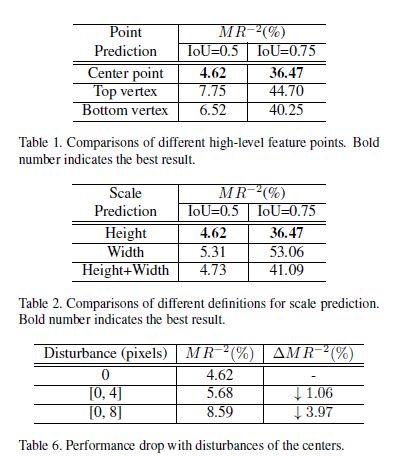
예시로 ResNet-50 사용하였다. Convolution 레이어를 5단계로 나눌 수 있는데 이는 output feature map이 인풋 이미지에서 2,4,8,16,32로 다운샘플링이 진행될때를 기준으로 하였다. 그리고 5단계에서는 dilated convolution을 적용해 원래 이미지 사이즈의 1/16을 유지하도록 하였다. 2,3,4,5 단계에서 추출된 피처맵을 φ2, φ3, φ4, φ5 로 나타낼수 있으며, shallower 피처맵은 더 정확한 위치정보를 포함하는 반면에 coarser ones은 semantic 정보를 포함하고 있다. 그래서 각 단계에서 나온 multi scale 피처맵을 하나의 싱글맵으로 간단히 합쳤다. 그 방법은 각 피처맵에 deconvolution layer를 적용해 같은 resolution으로 만들고 concatenation으로 합쳤다. 이때 피처맵은 각각 다른 스케일으 가지고 있기 때문에 L2-norm으로 rescale하였다. 그리고 우리는 이런 피처맵들의 조합에 대해서 ablative experiment 을 수행하였고 아래 표에 나타냈다. 그리고 실험결과 가장 최선의 조합은 Φdet = {φ3, φ4, φ5} 다. 입력 이미지의 사이즈가 H x W일때, 최종적으로 합쳐지는 피쳐맵의 사이즈는 H/r x W/r이다. 이때 r은 다운샘플링 factor로 실험결과 r=4일때 가장 좋은 성능이 나타났다. 그 이유로는 r이 커지면 coarser 피처맵은 localization의 정확성이 떨어지고, r을 작게하면 계산량이 많아진다.
Detection Head
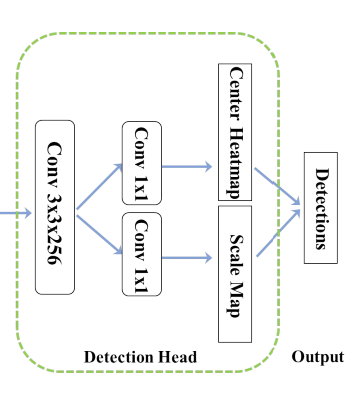
위에서 만든 결합된 피처맵인 Φdet 를 가지고 이제 detection을 수행해야한다. 이때 detection head는 좋은 성능에 결정적인 역할을 수행한다. 이 연구에서는 가장먼저 single 3×3 Conv layer를 통해 Φdet 의 차원을 256차원으로 감소시켰다. 그리고 두개의 1×1 Convolution 레이어를 만들고 하나는 center heatmap을 위해서 다른 하나는 scale map을 생산하도록 하였다. 다운샘플링을 통해서 얻은 피처맵의 단점은 localization정보가 빈약하다는 것이다. 그래서 우리는 center locationlayer에 offset 예측 브랜치를 추가하였다.
Training
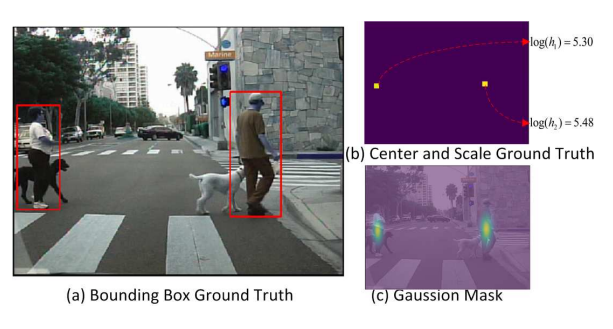
Ground Truth
우리는 주어진 bounding box annotation을 center와 scale 학습을 위한 GT로 자동 변환하였다. 위의 그림에서 (b)를 보면 GT center와 scale이 나타나있다. object의 center는 positive이고 반면 나머지는 negative로 지정했다. scale도 객체의 height 또는 width로 정의할 수 있다. 보행자 인식을 위한 고퀄리티의 GT를 얻기위해 aspect ratio가 0.41로 균일하고 타이트한 바운딩 박스를 갖는 데이터셋을 사용하였다. 이를 통해 각각 개체의 높이를 미리 예측하고 지정된 aspect ratio를 갖는 bounding box를 생성한다. scale GT를 위해서는 k번째 positive loacation을 log(h_k)의 값으로 지정하였다. 이때 ambiguity를 줄이기위해 positive의 반경 2이내 있는 negatives도 log(h_k)로 지정했다. 그리고 나머지 모든 location은 zero로 설정했다. 다른 방법들( width를 설정하거나 widt+hight를 설정하거나)도 사용했지만 성능으 좋지 못했고, 이에대한 실험결과는 아래에 나타냈다. offest prediction branch를 추가했는데 center의 offset을위한 gt는 다음과 같이 정의하였다.
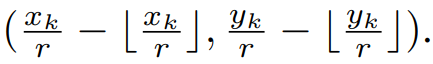
Loss function
center prediction branch를 위해 우리는 classificatino 문제를 cross entropy loss로 공식화하였다. 우리는 정확한 중심점을 찾기가 어렵다는 것을 알았고, 어렵게 지정된 positive와 negative가 학습을 어렵게 만들었다. 우리는 이러한 negative로 둘러쌓인 positive가 갖는 ambiguity를 줄이기위해서 우리는 2D Gaussian mask를 적용하였고 이를 G(.)로 나타냈다. 마스크맵 M은 Fig3 (c)에 나타나며 공식은 아래와 같다.
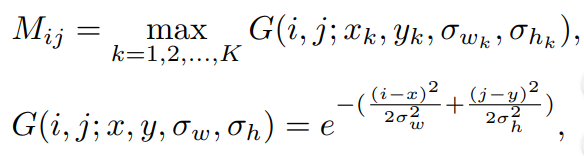
이때 K는 이미지당 객체의 갯수이며, (xk, yk, wk, hk) 는 중심점 좌표값이다. 가우시안 마스크의 분산 (σ k w, σk h )는 각 객체의 height와 width의 비율이다. extreme positive negative imbalance problem을 피하기위해 hard exampl에 focal weight를 적용하였다. 따라서 classification loss는 아래 공식과 같다.
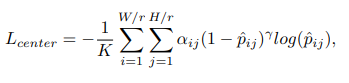
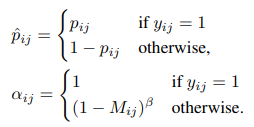
위에서 pij 는 네트워크가 추정하는 probability를 나타내며 이는 (i,y) 좌표가 object의 center인지 아닌지를 의미하는 확률이다. 그리고 yij는 1일때 positive location을 의미한다. αij 와 γ 은 focusion hyper parameters인데, 우리는 실험적으로 γ 는 2로 설정하였다. 모호성을 줄이기위해 negative는 positive를 둘러싸고있고, 이때 αij 에 따라 가우시안 마스크 M의 total loss에 대한 기여도는 줄어든다. 또한 β 는 패널티를 조절한다. 실험적으로 β =4가 가장 좋은 성능을 보였다. positibe에 대해서 αij 는 1이다. scale prediction을 위해 우리는 regression task를 smooth L1 loss로 아래와 같이 나타냈다.
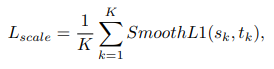
종합적인 loss는 아래와 같다.
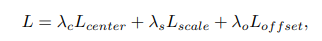

기타 Data augmentationo과 inference는 위의 그림을 통해 나타낸다. (내용에 어려움이 없어서 바로 읽힌다.)
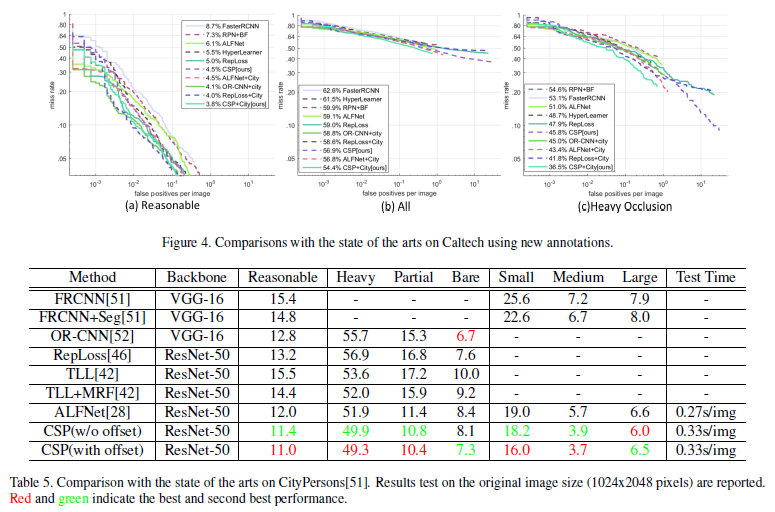
Experiments