이전 부터 LiDAR를 이용한 Localizaion에 대한 연구가 궁금했었습니다. 때마침 아카이브에 올라오기도 했고 Vision base와도 결합한 방식이라고 하여 친숙하게 접근할 수 있을거라 생각해 리뷰를 해보도록 결정했습니다.
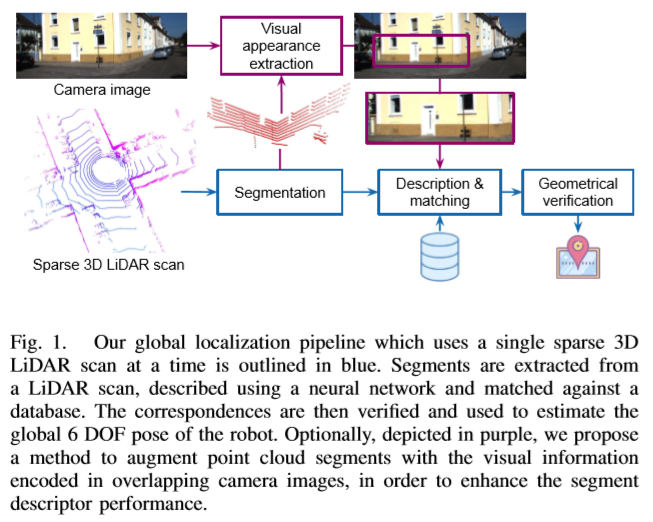
해당 연구는 Single sparse LiDAR(ex.16 scan line) data와 영상을 이용한 Descriptor를 triplet loss를 이용하여 학습(NN)하고 추론된 Descriptor로 6 DOF를 구합니다.
Lidar based descriptor는 Segment based approach인 SegMap[1]을 확장한 OneShot(해당 연구)와 Visual based descriptor는 vgg16 based NetVLAD을 이용합니다.
대략적인 파이프 라인은 Figure 1.(우측 그림)을 참고 하시면 됩니다.
해당 연구에서 기여한 바는 다음과 같습니다.
- OneShot : 단일 스캔(at a time)을 이용한 3D-LiDAR 기반 Global Localization – 6 DOF 추정 방법
- 영상과 Lidar based descriptor 결합하여 추론함으로써 성능을 향상
- KITTI(wake-up scenario, sequence 00), NCLT(Long-Term Vision and Lidar)에서 SOTA를 달성
One-Shot LiDAR Loclization
이전의 Segment based LiDAR-Localization들과는 다르게 Single Lidar scan at a time(단일 Lidar로 한번에 스캔)한 data(= single sparse Lidar scan data)(ex. 16 scan line, Figure 2. 좌측)에서도 강인함을 보여주는 방법이다.


A-LiDAR. Segmentation
Figure 2. 좌측 이미지처럼 Segmentation을 하기 위해서 [2] 방법(Table 1.)을 이용 합니다. 해당 방법으로 불연속적인 depth를 가진 point cloud들을 간단한 geometry로 분리합니다. (구체적 언급을 논문[2] 맵핑으로 끝냄..)
A-Vision. Image Patch
Lidar와 camera가 overlap한 시야를 가졌다고 가정했을 때, LiDAR에서의 segments들을 image에 projection된 부분들을 Image Patch로 사용합니다.
B-LiDAR Segment Description
SegMap [1]의 모델(Figure 3.)과 유사한 형태를 취하고 있으며, Loss는 triplet Loss를 사용하여 학습하도록 변경했다고 하였고. sparse Lidar data를 취급하므로, 새롭게 training 시켜서 사용했습니다.
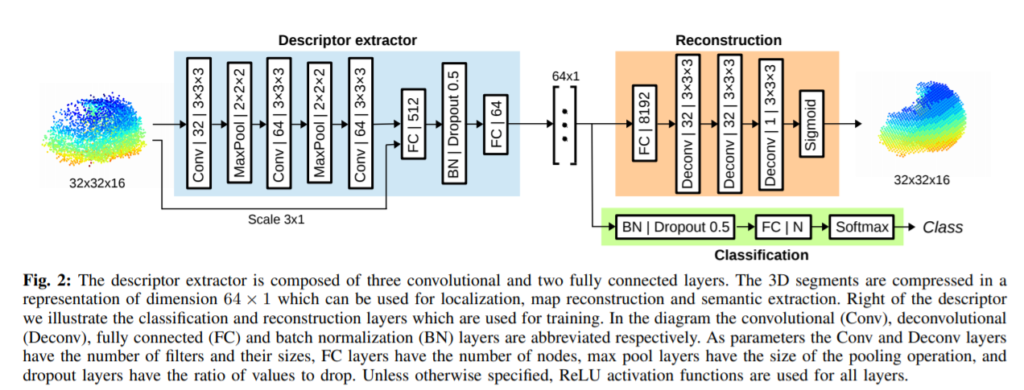
B-Vision. Vision Based Descriptor
Vgg16 based NetVALD를 사용하여 4096 x 1 차원을 가진 descriptor를 추출합니다.
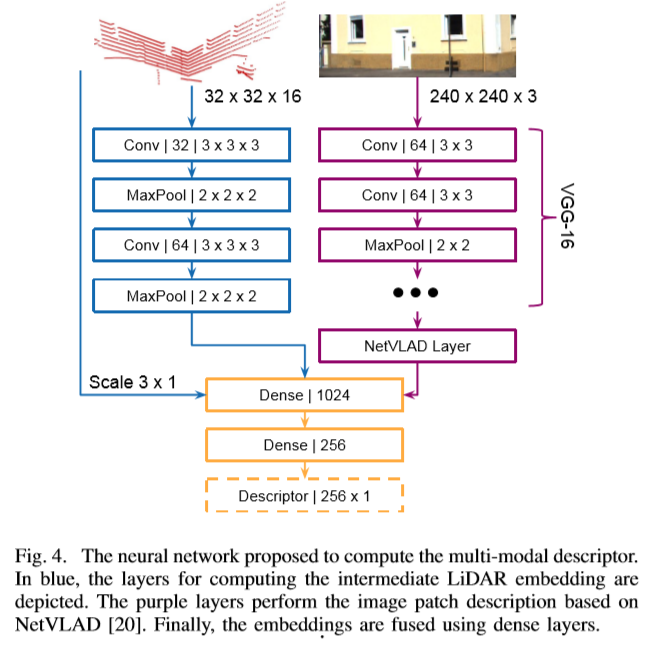
C. Neural Network (Figure 4. 하단의 그림)
- Vision, LiDAR based descriptor를 Concatenated 시키고, 응축시킴으로써 256 x 1 차원을 가진 응축된 Multi-modal Descriptor를 획득함
- Loss는 triplet Loss를 사용하며, 잘못 지정된 라벨에 대해 민감성을 줄이기 위해서 Batch hard[3]을 이용함.
- KITTI : sequence 05, 06 (training) / seq 00 (testing)
- NCLT : 2012-11-17, 2012-03-25 구역을 구분하여 셋을 나눔
D. Segment Matching
- Segment + 중심 위치가 포함된 DB (K-d tree)
- k-nn을 통해 query을 retrieval 함.
E. Geometric Consistency Test
- Segment Descriptor는 Geometry Consistency Test를 함.
- Consistency Graph[4]에서 Maximum Clique을 찾습니다.
- Consistent map과 Segment DB에서의 중심값간의 거리의 least squares problem을 풀면 6 DOF를 구할 수 있음[4]
[1] R. Dub´e, A. Cramariuc, D. Dugas, J. Nieto, R. Siegwart, and C. Cadena, “SegMap: 3d segment mapping using data-driven descriptors,” in Robotics: Science and Systems (RSS), 2018.
[2] I. Bogoslavskyi and C. Stachniss, “Fast range image-based segmentation of sparse 3d laser scans for online operation,” in Proc. of The International Conference on Intelligent Robots and Systems (IROS), 2016.
[3] A. Hermans, L. Beyer, and B. Leibe, “In defense of the triplet loss for person re-identification,” CoRR, vol. abs/1703.07737, 2017.
[4] R. Dub´e, M. G. Gollub, H. Sommer, I. Gilitschenski, R. Siegwart, C. Cadena, and J. Nieto, “Incremental segment-based localization in 3D point clouds,” IEEE Robotics and Automation Letters, vol. 3, no. 3, 2018.
PS. 제안한 방법이 아닌 방법들은 전부 해당 논문으로 맵핑 시켜 설명하여 제대로 이해할려면 다른 논문까지 읽어야 했습니다. 그래서 내용이 빈약한 부분이 있기에 양해 부탁드립니다. 특히 1저자가 [1] SegMap 저자이기도 하고, 해당 연구는 SegMap에서 Vision을 결합한 확장 연구라고 합니다. (SegMap에서도 Multi-Modal을 Future work로 작성을 해두었더라구요.) 그래서 그런지 SegMap에서 언급한 방법은 생략된 부분이 많아 시간이 날 때, SegMap을 제대로 봐야 이해가 될 듯 싶습니다.