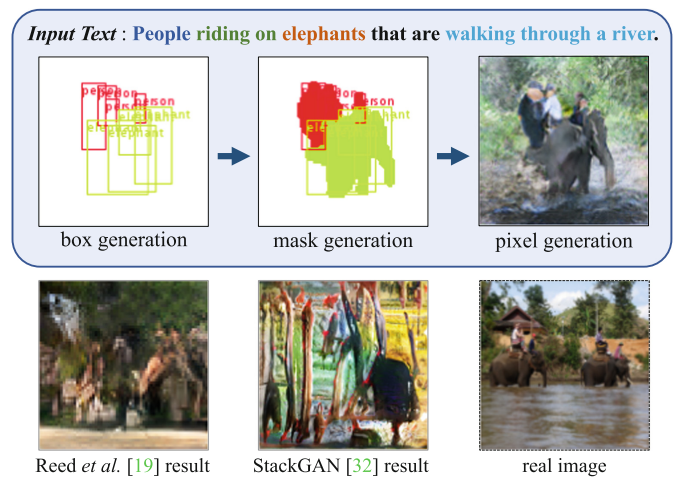
이미지와 text 매칭에 관련한 논문이다. 기존의 방식은 텍스트와 이미지를 직접 매칭 했다면, 이 제안 방식은 위의 그림에서 확인할 수 있듯이 먼저 box generation으로 위치를 매칭 하고 그 이후 mask generation으로 모양을 지정한 후, pixel generation으로 최종적으로 매칭하는 방식으로 진행한다.
아래 결과에서 확인할 수 있듯이 비슷한 방법론들과 비교하여 가장 잘 작동한다 생성시에 GAN Loss와 확률에 관련된 Loss를 사용하였다.
Loss를 많이 사용하여 전부 적지는 않았지만 대표적으로
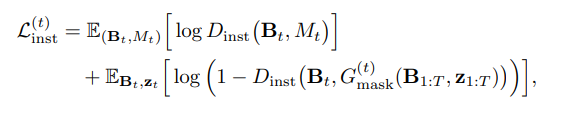
이러한 형태를 지녔다.

(물론 Loss도 제안하였지만) 진행 방식을 바꾼것 만으로 이렇게 성능향상을 냈다는것이 신기하다..