with The Pyramid Match Kernel: Discriminative Classification with Sets of Image Features
Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories 는 bag of visual word (이하 bovw)방법을 개선한 방법에 대한 논문입니다.
이 때 사용한 kernel은 The Pyramid Match Kernel:Discriminative Classification with Sets of Image Features 여기서 제안 되었습니다.
이번 X-review에서는 Support Vector Machine을 중점적으로 설명해보겠습니다.우선 bovw란 bag of word(이하 bow)라는 문서에서 단어를 취합하고 이를 통해 어떤 문장에 어떤 단어들이 있는지 파악하는 문서 분류 아이디어를 컴퓨터비전 분야에서 응용하여 문장 대신 사진 단어 대신 feature를 가지고 이미지 분류를 진행합니다.
bovw의 과정은 다음과 같습니다.
- Feature Extraction: 이미지들로부터 feature를 추출한다 (SIFT 등)
- Clustering: 추출된 feature들에 대해 클러스터링을 수행하여 클러스터 센터(center)들인 codeword들을 찾아낸다. 클러스터링 방법은 보통 k-means clustering이 사용된다.
- Codebook Generation: 찾아진 codeword들로 구성되는 코드북을 생성한다. 코드북은 물체 클래스마다 생성하는 것이 아니라 <그림 2>의 예와 같이 공통적으로 하나만 생성되며 모든 클래스의 codeword들을 포함한다.
- Image Representation: 각각의 이미지들을 codeword들의 히스토그램으로 표현한다. 이미지 하나당 하나의 히스토그램이 나오며 이 히스토그램의 크기(bin의 개수)는 코드북의 크기(코드북을 구성하는 codeword들의 개수)와 동일하다.
- Learning and Recognition: BoW 기반의 학습 및 인식 방법은 크게 Bayesian 확률을 이용한 generative 방법과 SVM 등의 분류기를 이용한 discriminative 방법이 있다. Bayesian 방법은 물체 클래스별 히스토그램 값을 확률로서 해석하여 물체를 분류하는 것이고, discriminative 방법은 히스토그램 값을 feature vector로 해석하여 SVM(support vector machine)등의 분류기에 넣고 클래스 경계를 학습시키는 방법이다.
여기서 SVM은 어떻게 클래스 경계를 학습할까요?
SVM은 기본적으로 이진 분류기입니다. 이진분류법을 확장해서 멀티클래스 분류를 하는 방법이 있는데 대표적으로 one vs one 그리고 one vs rest이 있습니다


Svm은 기본적으로 선형분류를 합니다. 하지만 어떤 직선을 그어도 두 범주를 완벽하게 분류하기 어려운 경우도 많습니다. Kernel-SVM은 이 문제를 해결하기 위해 제안됐습니다.원공간(Input Space)의 데이터를 선형분류가 가능한 고차원 공간(Feature Space)으로 매핑한 뒤 두 범주를 분류하는 초평면을 찾습니다.
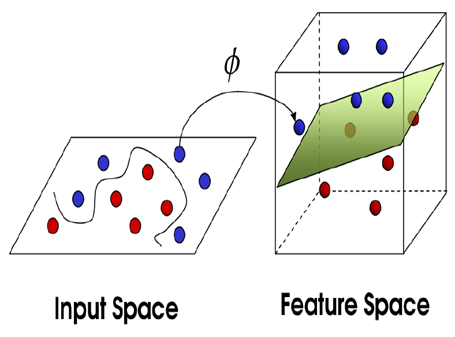
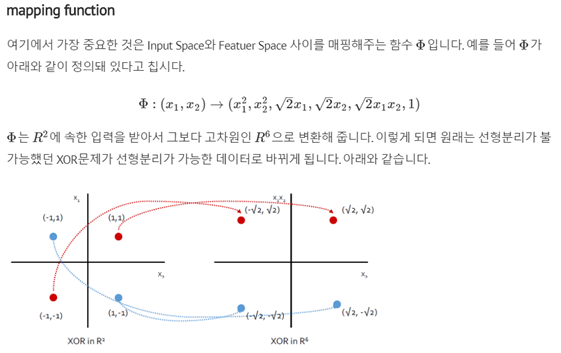
모든 관측치에 대해 고차원으로 매핑하고 이를 다시 내적(inner product)해야 하기 때문에 연산량이 폭증하게 됩니다.고차원 매핑과 내적을 한방에 할 수는 없을까요? 이를 위해 도입된 것이 바로 커널(Kernel)입니다. 커널 K는 다음과 같이 정의됩니다.


Spatial Pyramid Matching
: Pyramid Match Kernel
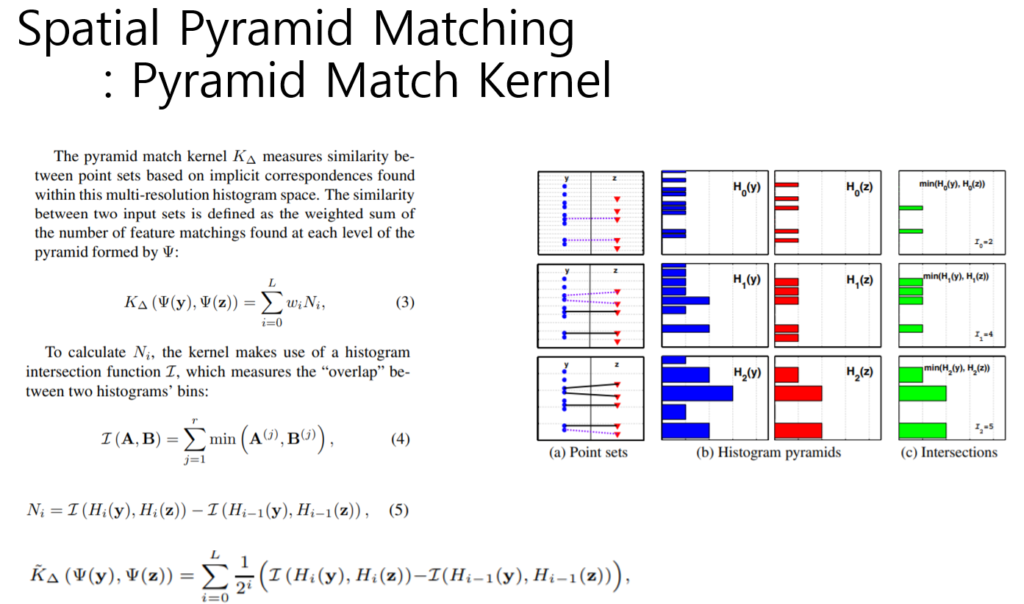
위와 같이 pyramid match kernel은 가중치*intersection의 시그마 합으로 정의됩니다.


위와 같은 이유로 mercer’s condition을 만족함을 보여서 kernel로 사용하고 있다고 합니다.
이를 Beyond Bags of Features: Spatial Pyramid Matching for Recognizing Natural Scene Categories에서는


다음과 같이 쓰고 있습니다.