
논문: Improving 3D Object Detection through Progressive Population Based Augmentation
머신러닝 모델을 훈련할 때 성능을 높이기 위한 방법은 model structure 뿐만 아니라 data augmentation, optimizing, metrics 등과 같이 다양한 방법들이 있습니다.
최근 들어 구글은 Quoc V. Le 와 같은 연구원을 중심으로 AutoML 연구를 많이 하고 있습니다. MnasNet[1]은 model structure를 기계가 스스로 학습하여 성능을 크게 끌어올렸고, AutoAugment[2]는 2D 이미지를 분류할 때 data의 augmentation 방법을 스스로 학습한 연구입니다.
그리고, 이번에 3D point cloud data를 AutoML 방법으로 data augmentation한 Progressive Population Based Augmentation(PPBA) 방법을 소개했습니다. PPBA는 augmentation parameters를 좁은 범위로 줄여나가면서 모델을 학습하는 중 직전 단계의 가장 좋은 성능을 보여준 parameters를 적용하는 방법입니다. Augmentation strategies는 총 8개로 그림1 을 통해 직관적으로 알 수 있고, 각 augmentation들의 parameters 들은 21개이며, 이 둘의 합 29개의 parameters를 학습하는 것이 목표입니다. (각 strategies와 parameters의 설명은 논문의 appendix를 참고해주세요.)
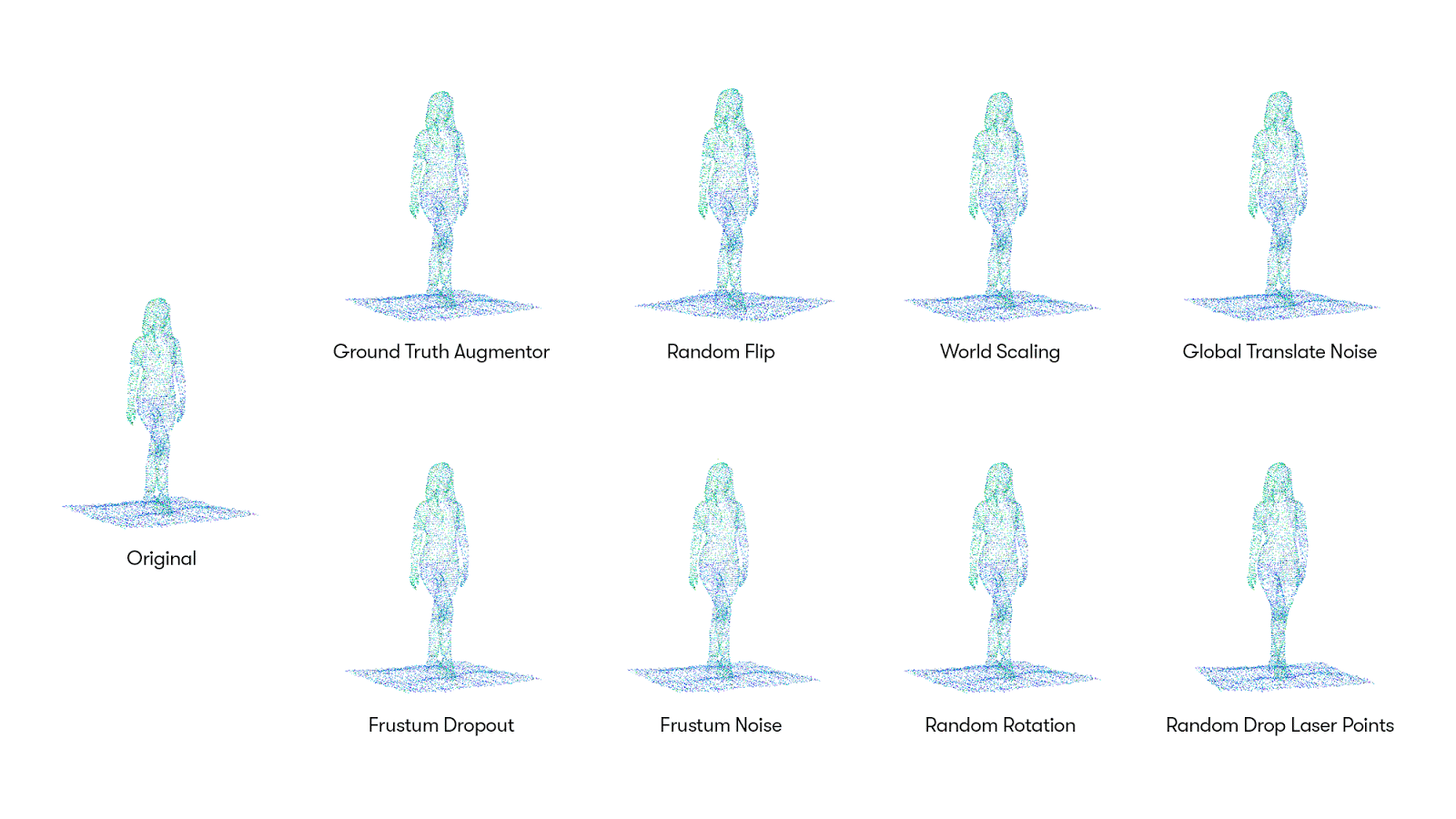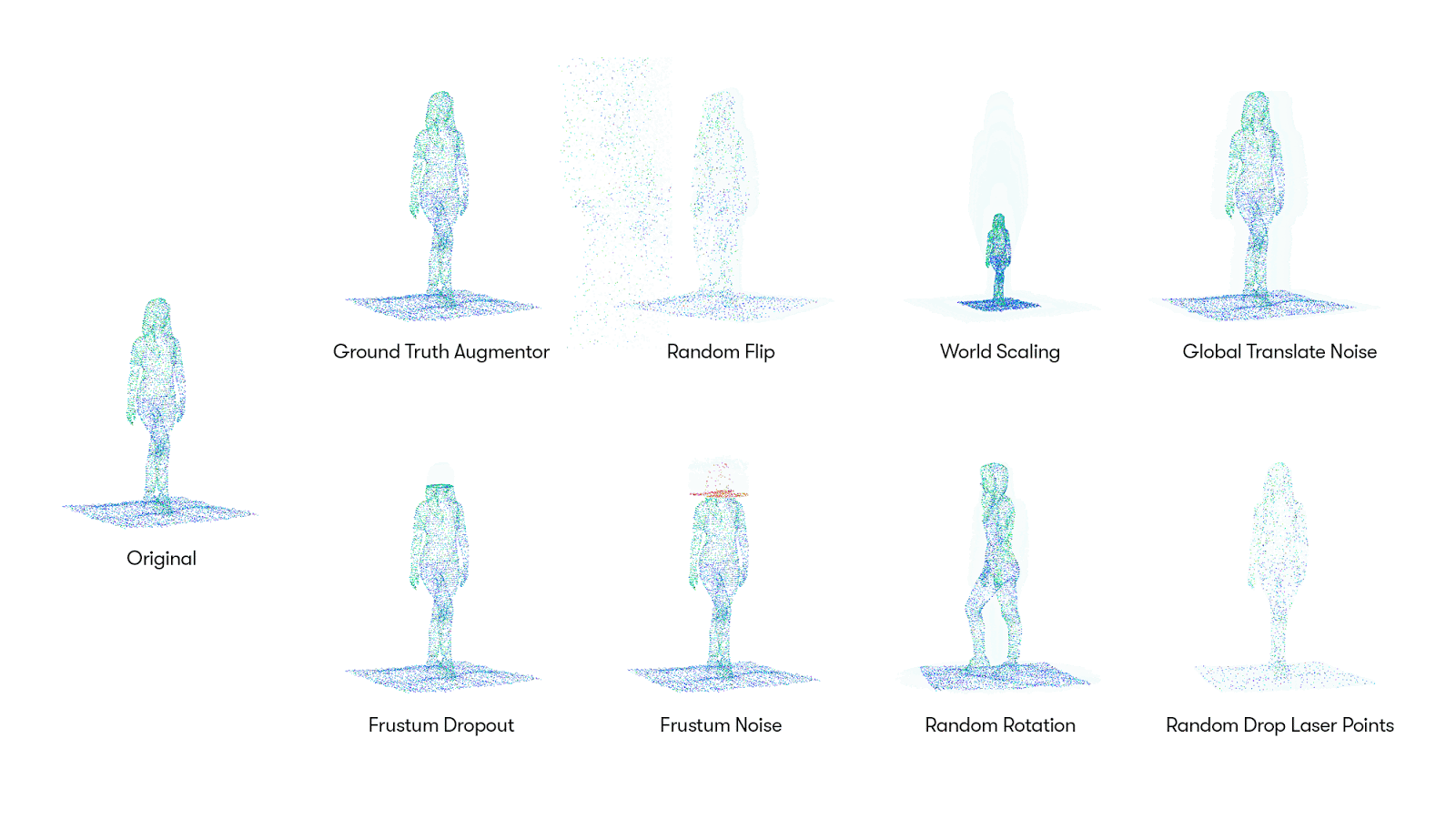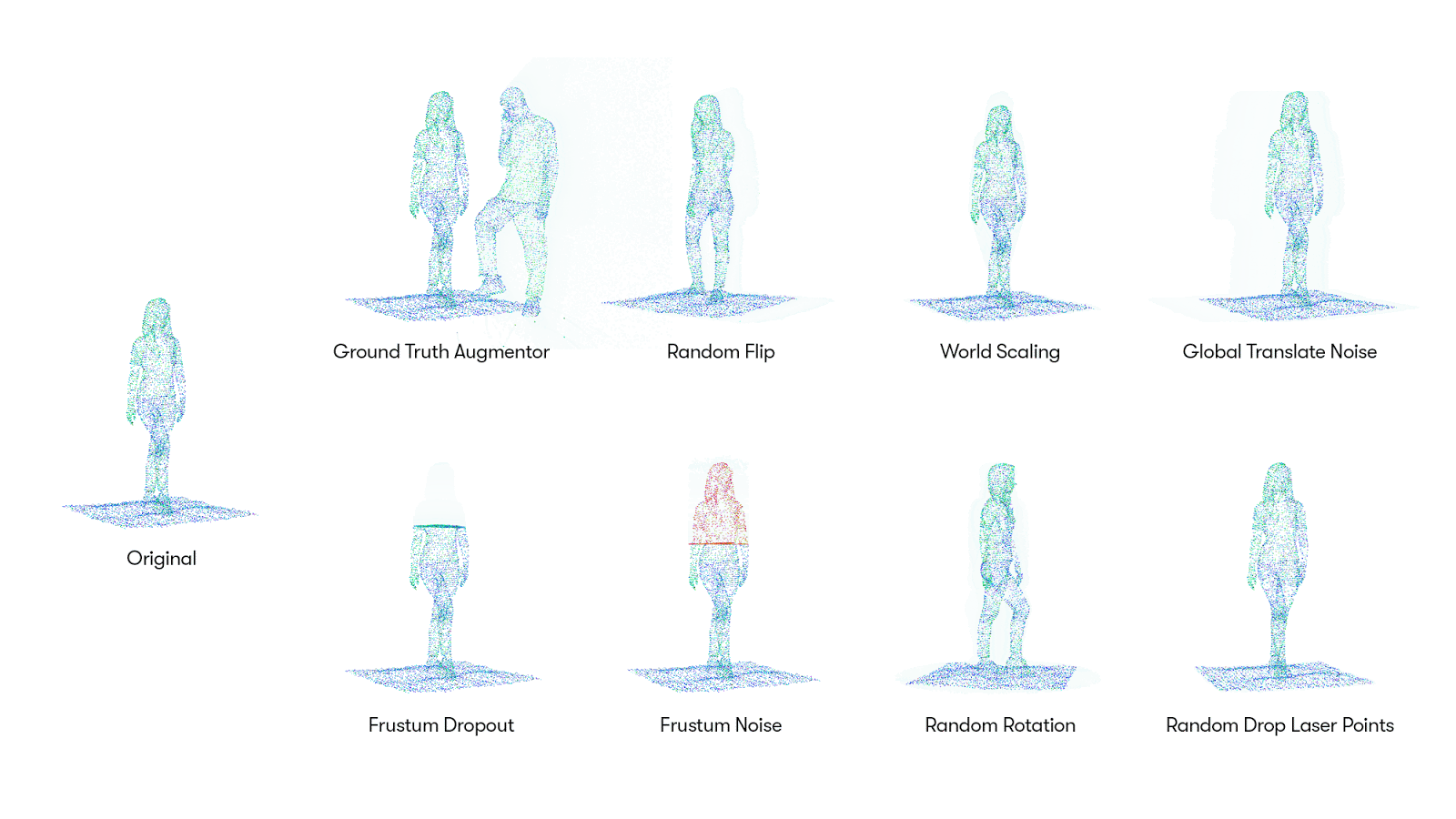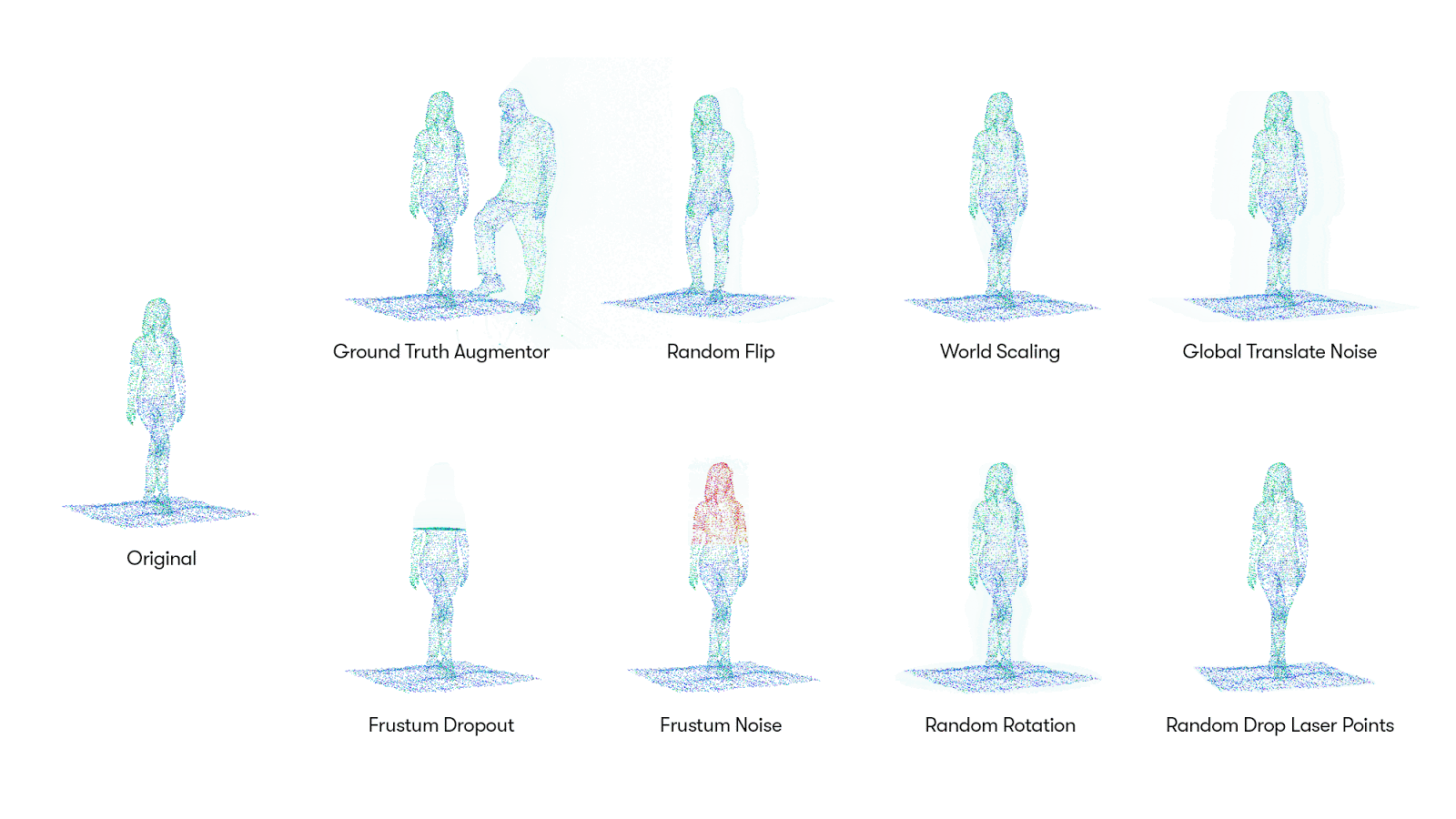
PPBA를 알기 위해 Population Based Augmentation(PBA) [4]에 대해 간략히 설명하자면, 그림2. 와 같이 모델들을 병렬적으로 학습시키는 것 중 모델을 경쟁시켜 승자를 선택하고 그 모델을 바탕으로 훈련하는 것을 말합니다. PPBA도 마찬가지로 초기에는 random parameters들을 학습하고, 학습을 진행하면서 성능이 가장 좋은(winner) parameters와 직전 단계의 parameters를 다시 비교하여 더 좋은 성능을 보여준 parameters를 선택하고(mutate), 이 과정을 반복하게 됩니다. (본 논문의 알고리즘1, 2를 보면 보다 더 직관적으로 알 수 있습니다.)

성능 향상을 보여주기 위해 두 종류의 결과 비교를 했습니다. (1) 데이터셋을 고정 시킨 후 비교 (KITTI[6], Waymo Open Dataset[7]), (2) 훈련 시키는 데이터셋의 비율을 변경하여 비교를 진행했습니다. 표1. , 표2. 과 같이 데이터셋 크기가 작은 KITTI 뿐만 아니라 약 20배 더 큰 Waymo Open Dataset에서도 PPBA가 성능 향상을 주고 있다는 것을 알 수 있습니다. 이점을 유념히 살펴본 것인지 훈련 데이터의 일부만 사용하여 성능이 얼마나 나오는지 비교해보았는데(표3.) sampling 방법에 따라 데이터를 100% 사용한 것에 비해 30%, 10% 사용한 정도만으로도 baseline의 100% 성능과 비슷하게 나오는 것을 알 수 있습니다.
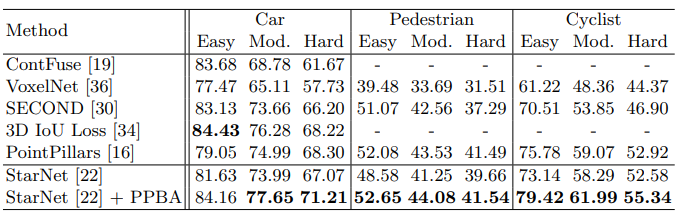
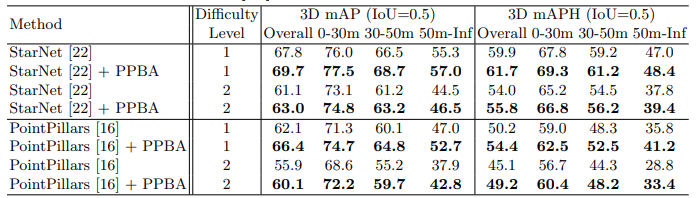
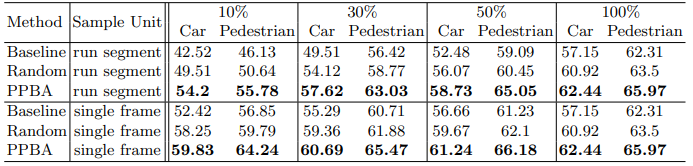
또 다른 실험으로는 훈련에 사용한 자원을 비교하였는데(표4.) KITTI를 사용하여 StarNet[8]으로 훈련할 경우 manual design은 8 TPU 시간이 필요하고, random하게 찾으면 8000 TPU 시간, PPBA는 128 TPU 시간을 걸렸다고 합니다.

본 논문을 통해 2D 뿐만 아니라 3D point cloud에서도 기계가 데이터를 자동으로 augmentation 해주는 전략에 대해 알 수 있었습니다. 또한, 구글은 사람이 기본적인 {augmentation, layer, …} 방법을 정해주면 기계가 스스로 학습할 수 있는 연구에 투자를 하고, 전체 파이프라인에서 하나씩 해결해 나가는 것을 확인할 수 있습니다. 이 전략이 성능과 효율성을 좋게 하는데 동의하지만 결국 기본 방법에서 한정된 것이라 더 좋은 아이디어를 적용한 사람의 연구가 계속 필요하다고 생각됩니다.
참고:
[1] MnasNet: Platform-Aware Neural Architecture Search for Mobile
[2] AutoAugment: Learning Augmentation Policies from Data
[3] Using automated data augmentation to advance our Waymo Driver
[4] Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules
[5] How Evolutionary Selection Can Train More Capable Self-Driving Cars
[6] KITTI: 3D Object Detection Evaluation 2017
[7] Waymo Open Dataset
[8] StarNet: Targeted Computation for Object Detection in Point Clouds