참고논문: Leveraging Deep Visual Descriptors for Hierarchical Efficient Localization, CoRL2018.
Github: https://github.com/ethz-asl/hierarchical_loc
Visual Localization 이란 간단하게 말하면 이미지만으로 촬영위치를 알아내는 것입니다. Visual Localization 중 3D camera 의 6-DOF pose estimation 까지 하는 방식을 잘 보여주는 논문이라 생각해 골라 봤습니다.
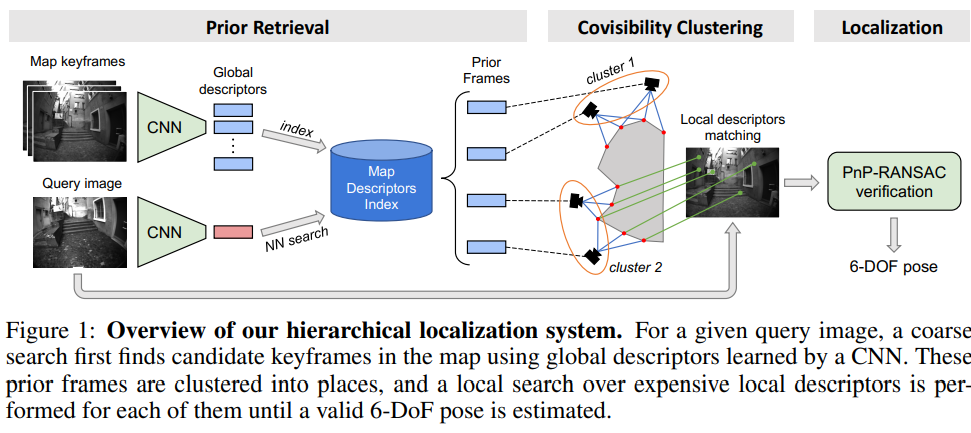
Visual localization 은 [그림 1]과 같은 시스템으로 흘러 갑니다.
- Prior Retrieval: Map 영상의 Global Descriptor를 기술 하고 Database를 구축합니다. 그리고 Query 의 Global Descriptor 와 유사한 영상들로 retrieved 된 Prior Frames를 Retrieved 합니다.
- Covisibility Clustering: 3D상에 올리고 그 중에서 같은 keypoints 를 공유하는 frame 끼리 clustering 합니다. Clusters의 각 영상과 Query 의 local descriptor 를 3D point matching 하여 keypoint를 찾는다.
- Localization: 위 과정을 통해 얻는 정보를 가지고 PnP-RANSAC 를 이용해 판단한 후 가장 알맞은 pose를 찾으면 프로세스는 종료된다.
이러한 과정들 중 이 논문이 제시하는 키아이디어를 정리하면 다음과 같다.
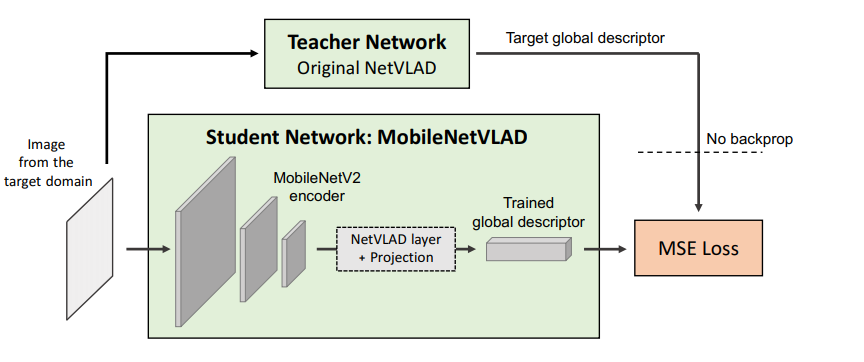
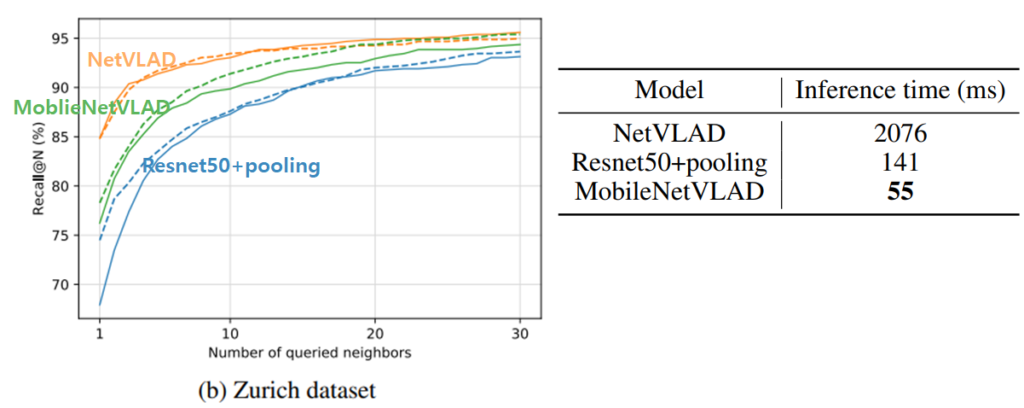
- Prior Retrieval의 feature 경량화: Global Descriptor 정의를 위한 Model를 제시했습니다. NetVLAD를 Teacher network 로 활용해서 가벼운 MobileNetVLAD를 학습하는 방식의 Network를 채택하여 실시간 Localization에서 필요한 모델의 경량화를 했습니다. 그림 3 과 같이 NetVlad를 사용했을 시 보다 성능은 거의 차이 나지 않지만 속도적 측면에서 거의 40배 가까이 차이나는 것을 볼 수 있습니다.
- Covisibility Clustering: retrieved 영상끼리는 많은 특징점을 공유할 것이다. 이때 같은 keypoint를 공유하는 frame 끼리 군집화 하여 뒷단의 프로세싱을 진행 하면 더욱 빠르게 estimation을 진행할 수 있다고 합니다.
Retrieved시 KNN을 할때 사용하기 편한 C++ Catkin package를 사용했고, localization에 필요한 tool은 MapLab을 사용했다고 합니다.
이 논문은 전체적인 파이프라인을 통해서 6-DoF를 estimation 하는 과정을 조금이라도 이해하기 좋은 거 같습니다. 비록 아직 2D-3D사이의 관계를 통한 방식을 잘 알지 못해 최종 과정을 자세히 이해할 순 없지만 , 이 과정을 이해하고 이 뒤에 나오는 DNN 방식의 Localization을 이해하기 더욱 받아드리기 좋을 것 같습니다.