참고논문: Faster R-CNN : Towards Real-Time Object Detection with Region Proposal Networks, NIPS2015.
Github: https://github.com/rbgirshick/py-faster-rcnn
Faster R-CNN에 대해서 제가 이해한만큼 정리해보려고 합니다.
Abstract
먼저 object -detection network들 중에서 region based CNN (eg R-CNN)이 좋은 성능을 내고는 있지만, 학습 및 실제 적용에 있어서 많은 시간과 GPU 계산 용량을 차지합니다. 그나마 SPP-Net 또는 Fast R-CNN을 통해서 위에 문제들을 해결하였지만, region proposal을 구하는 것에 있어서는 아직도 병목이 심하게 존재합니다. 이러한 병목을 해결하고자 Faster R-CNN 논문에서는 Region Proposal Network(RPN)를 제안합니다. RPN은 Detection Network (localization & classfication) 속에서 전체 영상의 Convolutional Features를 공유하기 때문에 region proposal을 찾는 비용이 거의 없다고 봐도 무방합니다. 이러한 RPN과 Fast R-CNN을 하나로 합친 단일 네트워크는 빠른 속도와 높은 정확도를 가져다왔고 ILSVRC와 COCO 2015 competition 여러 부문에서 1등을 차지했다고 합니다.
INTRODUCTION
Abstract에서 했던 말을 또 얘기하는거라 간단하게 소개를 드리면

- 기존 R-CNN은 크게 region proposal 부분과 CNN feature 계산, Classification으로 나뉩니다.
- 세가지 파트를 학습시켜야 했고, 2000여개의 region을 각자 계산했으므로 많은 시간과 연산량이 소모됩니다.
- 이를 해결하기 위해 Fast R-CNN에서는 그림1의 3번과 4번 과정을 하나의 네트워크에서 해결했지만 2번 과정이 병목을 잡고 있었습니다.
- Faster R-CNN에서는 RPN이라는 새로운 네트워크를 만들어서 region proposal을 큰 비용 없이(cost-free) 구합니다.
- RPN네트워크는 Input 영상의 전체를 CNN feature map으로 뽑은 후 이 feature map을 input으로 하여 proposal을 구하는 모델을 학습합니다.
- 이 때 input으로 사용한 feature map이 뒷단에 classifier 모델에서도 사용 (sharing) 되기에 불필요한 연산을 줄이고, 기존 연산정보를 활용한다는 면에서 속도를 크게 향상 시킨다고 합니다.
Faster R-CNN
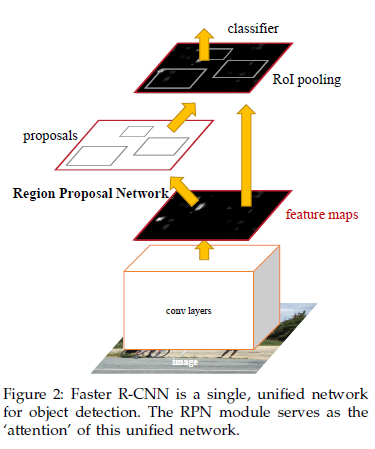
Faster R-CNN은 크게 region을 proposal하는 FCN 모듈과 proposed region을 통해 물체를 detect하는 Fast R-CNN detector 모듈 총 두 개로 이루어져있습니다.
How to propose region?
region을 propose하기 위해서 window를 Convolution feature map 위에 sliding 시킵니다. 이 window를 통해 나오는 feature는 box regression(reg)와 classfication(cls) layer를 통과합니다. 논문에서는 3×3 window를 사용했으며 이 window가 위치한 곳에 k개의 proposal region을 예측할 수 있습니다. 이러한 proposal을 box형태로 나타내는데 이를 anchor라고 부릅니다.
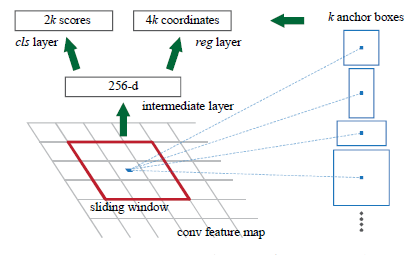
anchor는 sliding window의 센터에 위치하며, scale과 비율(aspect ratio)에 따라 개수가 정해지는데 논문에서는 3 scales, 3 aspect ratios를 통해 k=9의 anchor를 가집니다. convolutional feature map의 사이즈 W * H에 비례하여 총 WHk anchor가 존재하며, 각 anchor는 res layer에서 4개의 output(anchor의 x,y,w,h)와 cls layer에서 2개의 output( object or not object)으로 나타납니다.
요약하자면 RPN 모듈에서 input : convolution feature map, output : anchor의 bounding box와 score 라고 볼 수 있습니다.
Translation-Invariant Anchor
이 논문에서는 MultiBox method와 비교를 하였는데, 다음과 같습니다
- RPN의 경우 영상 속 물체가 translation 했다면, proposal도 translation 해야하며 이때 anchor와 관련된 proposal을 계산하는 함수 역시도 proposal을 translation의 맞추어 예측합니다.
- 반면 MultiBox method의 경우 K-means를 통해 800여개의 anchor들을 계산하는데 이는 translation의 불변성이 존재하지 않습니다.
- 또한 MultiBox method는 (4+1)*800 차원의 완전연결 층이 출력값이라면, RPN의 경우 (4+2)*9 차원의 컨볼루션 층이 출력 값으로 나오므로 모델 크기를 줄이는 효과도 존재합니다.
Multi-Scale Anchors as Regression References
multi-scale prediction을 위해서는 2가지 방법이 있는데 첫번째 방법은 바로 image/feature pyramids를 이용하는 것, 두번째 방법은 multiple scale의 sliding window를 사용하는 것입니다.
전자의 경우 image를 각각의 scale로 resize를 해야하고 이에 따른 feature map을 계산해야하기 때문에 시간과 연산량 소모가 큽니다.
후자의 경우(RPN) 다양한 scale과 ratio anchor를 통해(pyramid of anchors) bounding box를 분류하고 regression하므로 하나의 scale image & feature map만을 필요로 합니다.
Loss Function
RPN을 학습하는데 있어서, 먼저 각 anchor에는 binary class label을 분석해야합니다. 논문에서는 두 종류로 positive를 나누었는데, 첫번째는 GT박스와 가장 많이 겹치는 anchor/anchors를, 두번째 방식은 GT 박스와의 IOU가 0.7 이상인 경우입니다. 두번째 방식만으로도 충분히 positive label을 정할 수 있지만, positive anchor가 하나도 존재하지 않을 경우(non-positive anchor)를 대비하여 첫번째 방식도 적용한다고 합니다.
negative label은 IOU가 0.3보다 작은 경우로 정합니다. 이러한 조건을 통해 정해진 anchor들 중에 긍정도, 거짓도 아닌 anchor들은 학습에 사용하지 않습니다.
loss function에 대한 정의는 다음과 같습니다.
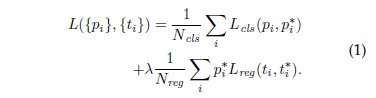
- i = index of an anchor in a mini-batch
- p_{i} = predicted probability of anchor i being an object
- p_{i}^{*} = ground-truth label (anchor가 긍정이면 1, 거짓이면 0값을 가집니다.)
- t_{i}^{*} = ground-truth box associated with a positive anchor
- L_{cls} = classification loss
- L_{res} = regression loss
- lambda = balancing parameter ( N_{cls} 는 256(mini batch size), N_{res} 는 anchor box 개수 (최대2400)으로 서로 불균형하기에 lambda를 통해 가중치를 정해줍니다.)
L_{cls} 는 2개의 class에 대한 log loss이며 L_{res} 의 경우 다음과 같은 4개의 coordinate들에 대한 연산을 취합니다.
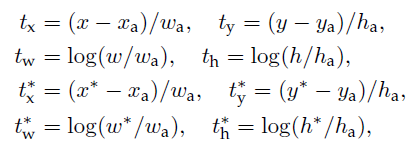
- x,y,w,h는 각각 box의 center 좌표 및 박스의 가로 세로 길이를 뜻합니다.
- x, x_{a} , x^{*} 는 각각 predicted, anchor, ground truth box를 뜻하며 같은 표기에 y,w,h모두 같게 정의됩니다.
위와 같은 연산을 취한 후에는, L_{res}(t_{i},t_{i}^{<em>*}) = R(t_{i},t_{i}^{</em>*}) 로 정의합니다. 이때 R은 robust loss function(smooth L1)입니다.
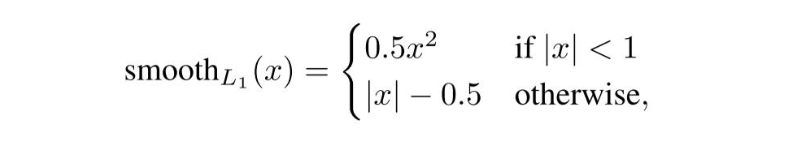
loss function 정의에서 p_{i}^{*} L_{res} 부분은 positive anchor일 경우에만 활성화되고, 아닐 경우에는 활성화되지 않습니다.
생각보다 양이 많아서 완벽하게 정리를 마치지 못했네요. 시간이 되면 추후에 보충하도록 하겠습니다.