참고논문: Deep Ordinal Regression Network for Monocular Depth Estimation, CVPR2018
Github: https://github.com/hufu6371/DORN
Abstract
3D 정보를 이해하는데 중요한 역할을 수행하는 Monocular Depth Estimation은 잘 정의되지 않는 문제(ill-posed problem)이다. 최근 Monocular Depth Estimation을 위해 image level information 과 CNN의 hierarchical features을 사용하였고, 큰 성능향상을 보였다.이러한 기존 Monocular Depth Estimation 방법들은 Depth Regression으로 문제로 해결하고 있으며며, MSE(Mean squared error)를 최소화하하는 방향으로 학습을 진행한다. 하지만 이러한 방법들에는 한계가 존재하는데, 학습하는 속도가 느리고, 불안정한 local solution을 가진다는 점이다. 또한 기존 Monocular Depth Estimation Network들은 반복적으로 spatial pooling operation을 수행하며 low resolution의 feature-map을 나타내는 것도 한계이다. High resolution depth map을 얻기위해서는 skip connections 또는 multi layer deconvolution networks를 사용해야하는데 이는 복잡한 네트워크 구조이며, 많은 계산량을 요구한다. 따라서 우리는 이러한 문제들을 개선하기 위해 depth의 이산화를 진행하는데 이를 위한 SID(spacing increasing discretization) 방법을 제안하고 있으며, Monocular Depth Estimation 의 전략을 Depth Regression이 아닌 ordinal Regression으로 변경하여 빠른 학습으로 더 높은 성능을 나타낼 수 있었다. 게다가 우리는 불필요한 spatial pooling을 피할 수 있고, multi scale에 대한 정보를 병렬적으로 수집할 수 있는 multi scale network 구조를 적용하였다. 이 논문에서 제안하는 방법은 KITTI, ScanNet, Make3D, NYU Depth v2 등 의 대회에서 SOTA를 달성하였고, Robust Vision Challenge 2018 에서는 1등을 차지했다.
SID(spacing increasing discretization)
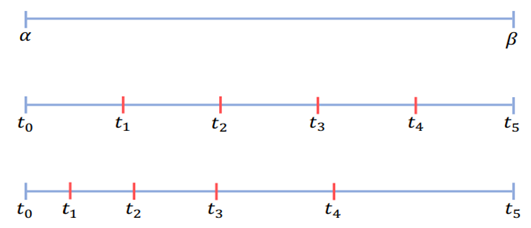
기존 Monocular Depth Estimation의 방법들은 Depth를 Regression으로 문제를 해결하고 Regression을 위해서 MSE나 MSE을 변형한 Loss function을 설계해 모델을 학습시켰다. 하지만 이때 문제점은 Depth는 0~무한의 값을 가지는데, Depth 가 멀어질수록 Depth Estimation을 위한 정보들이 많이 손실되고 이는 Depth Regression을 진행할 때, 큰 범위의 Depth값에서 더 큰 loss가 발생하고 이는 학습을 방해하거나 성능을 낮추는 요소가 될 수 있다고 저자는 이야기한다. 따라서 이러한 연속적인 형태의 Depth 값을 불연속적으로 특정 값들로 구분할 수 있는데 이를 이산화라고 이야기한다. 이산화에 정의는 연속적인 데이터를 부연속적인 점들로 변환하는 것을 이야기한다. 그렇다면 Depth를 어떻게 이산화를 하면 될까? 가장 기본적인 방법이 Uniform discretization(UD) 이다. 이는 위의 그림에서 두번째를 보면 된다. Depth의 값을 k로 나눌때, 최솟값(알파)과 최대값(베타)를 k등분하는 것이 UD방법이다. 단, 이렇게 나누게 된다면 여전히 앞서 말한 큰 범위의 Depth값도 들어가기 때문에 학습을 방해하거나 성능이 낮아질 수 있다. 따라서 이 논문에서는 SID(spacing increasing discretization)를 제안한다. 이는 Depth값을 로그 공간에서 균일하게 나누는 것을 의미하며, 수식은 아래와 같고 실제 그림은 위 그림의 세번째와 같다. 이는 큰 범위의 Depth에서 loss계산시 더 큰 loss가 발생하는 것을 줄일 수 있었고, 적은 범위의 Depth에서도 더욱 높은 추론이 가능하게 만든다.
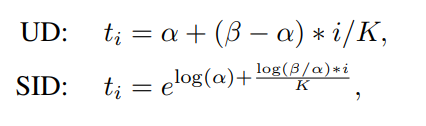
Ordinal Regression
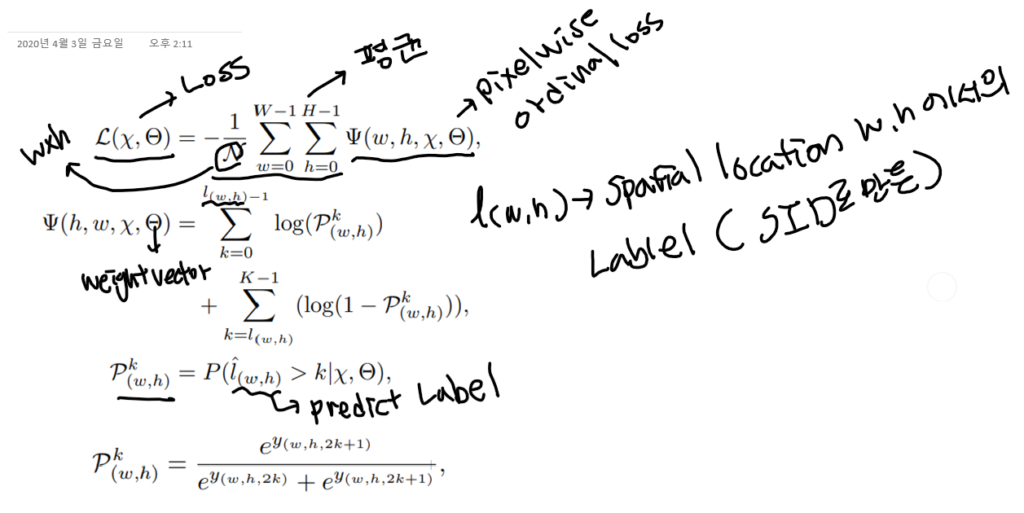
기존 Monocular Depth Estimation의 방법들은 Depth를 Regression으로 예측한다. Depth를 Regression으로 예측하는 방법은 학습에 많은 시간이 소모되고, 성능은 아직 많이 부족하다. 이 논문에서는 Depth Estimation을 standard Regression이 아닌, Ordinal Regression문제로 다시 설계하였고,이를통해 상대적으로 적은 시간 학습해 더 좋은 성능을 얻을 수 있었다고 말한다. Depth를 이산화하여 이를 multi-class classification 문제로 변경하는 것은 어렵지 않다. 그리고 multi-class로 변경시 softmax regression loss를 적용하면 된다. 하지만 이러한 방법은 이산화된 Depth 라벨들의 order 정보를 무시하게 된다. 실제 Depth는 well ordered set 의 형태이기 때문에 order 정보에 대해 강한 순서 상관관계(strong ordinal correlation)을 갖는다. 따라서 본 논문은 이러한 oder 정보를 최대한 살리기 위해서 ordinal regression을 문제를 변경하고 이러한 네트워크 학습을 위해 ordinal loss를 새롭게 설계했다고 한다.
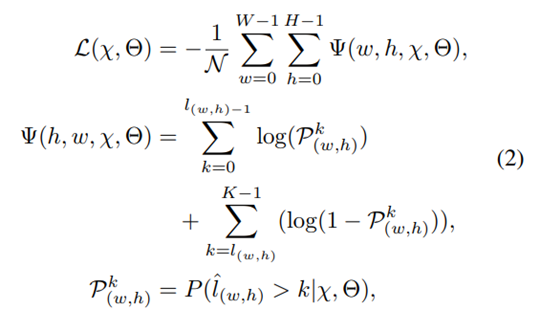
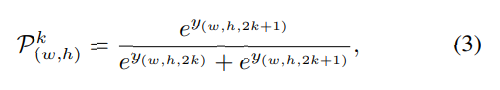
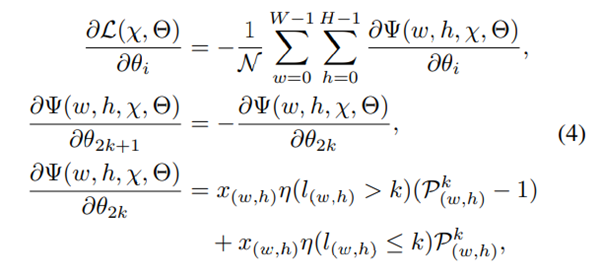
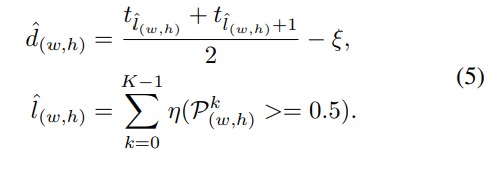
Network Architecture Network Architecture
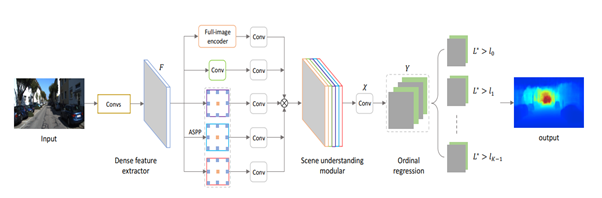
- Dense Feature Extractor
마지막으로 논문에서는 기존 CNN 기반 Monocular Depth Estimation 의 모델들은 반복적인 max pooling과 striding으로 feature map의 spatial resolution이 감소하는 것을 극복하기 위한 네트워크 구조를 설명한다. high resolution feature map일수록 더 좋은 depth estimation성능을 나타내는것은 당연한데, high resolution feature map을 얻기 위해서는 stage-wise refinement, skip connection, multi-layer deconvolution network로의 변경등의 방법이 있는데 이러한 것들은 네트워크가 복잡해지며, 계산량이 많아지고, 학습을 위한 메모리의 용량도 늘어난다. 이 논문에서는 이러한 것들을 개선하기 위해 최근 발표된 scene parsing network를 참고해 새로운 네트워크를 설계하였다. 추가적으로 몇 개의 다운샘플링 연산도 제거하는 동시에 파라미터의 증가와 spatial resolution의 감소 없이 각 필터가 보는 FOV를 확장시키기 위해 dilated convolution 연산을 진행하였다.
- Scene Understanding Modular
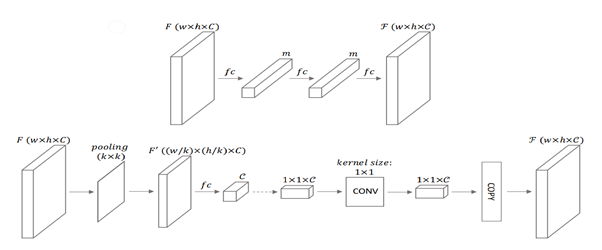
Scene Understanding Modular은 크게 3개의 병렬 성분으로 구성된다. Atrous spatial pyramid pooling(ASPP) 모듈, across channel leaner 모듈, 그리고 full image encoder 이다. ASPP는 dilated convolutional 연산을 통해 만들어진 multiple large receptive fields에서 추출된 피처를 사용한다. 이때 dilatation rate는 각각 6, 12, 18이고, pure 1×1 convolutional은 복잡한 corss channel interaction을 배울 수 있다. ful image encoder는 글로벌 contextual 정보를 capture해 깊이 추론에서의 지역 혼란을 점점 명확히 할 수 있다. 이전의 full image encoders 방법과는 다르게 우리는 몇가지 파라미터들을 추가적으로 포함시켰다. 위의 그림에 나타나듯 WxHxC채널의 F(가장 왼쪽) 로부터 WxHxC 채널의 global feature F(가장 오른쪽)를 얻는데 가장 보편적인 fc-fashion 방법은 fully connected layers를 사용하는 것이다. Global feature F의 모든 성분들은 모든 이미지의 피처들과 연결되는데, 이것은 전체 이미지에 대한 global 이해를 이야기한다. 그러나 이 방법은 엄청나게 많은 양의 파라미터를 포함하고 있고 이것은 학습하기 어렵고 메모리 소비가 많아진다. 대조적으로 우리는 spatial dimension을 줄이기 위해 작은 커널사이즈와 stride로 average 풀링을 만들어 사용했다. 그리고 이 풀링 뒤에는 C차원의 벡터를 얻기위한 fc layer를 사용하였다. 이를 통해 얻은 피처 벡터를 1x1xC채널의 피쳐맵으로 생각하였다. 그리고 a cross-channel parametric pooling structure의 1×1 커널사이즈의 레이어를 추가했다. 마지막으로 우리는 전체 이미지에 대해서 각각의 F벡터가 동일한 understanding을 공유하기 위해서 spatial dimension을 따라 피처 벡터 F를 복사하였다. 앞서 언급한 대로 만든 피처들을 입력이미지의 포괄적인 understanding을 위해 연결하였다. 또한 우리는 두가지 1×1 커널 사이즈를 갖는 2가지 레이어를 추가했는데, 하나는 피처의 차원을 줄이고 complex cross-channel interactions을 배우기 위해서고, 다른 하나는 피처를 multi-channel dense ordinal labels로 바꾸기 위함이다.
아이디어 & 논의방향
- 2.5D 진행시 SID를 통한 Depth 값 이산화가 필요하다
- 단순히 multi-classification이 아니라 ordinal loss의 적용이 필요하다
- 지금 논문은 Depth Estimation인데 해당 코드에 classification을 위한 (예를들면 Mask-RCNN의 역발상?) 추가하면 자동으로 2.5D segmentation문제가 되는거 아닌가?