Google brain에서 ICML2019에 model efficiency를 고려해 image classification network인 EfficientNet을 제안했고 ImageNet과 CIFAR-100, Flowers에서 state-of-the-art를 찍었습니다.
이에 후속작으로 CVPR2020에 model efficiency를 고려한 object detection network인 EfficientDet이 나오게 되었습니다. 그리고 EfficientNet과 마찬가지로 EfficientDet도 COCO dataset에서 state-of-the-art를 찍게 되었습니다.
EfficientDet의 특징은 크게 두가지로 볼 수 있습니다.
- Efficient multi-scale feature fusion (BiFPN)
- Model scaling (Compound scaling)
1. Efficient multi-scale feature fusion (BiFPN)
1.1 Weight feature fusion
FPN과 같은 multi-scale feature fusion 방식에 이어 PANet, NAS-FPN과 같은 cross-scale feature fusion 방식이 detection 성능을 올리는 데 도움을 주고 있습니다. 그러나 저자는 cross-scale feature fusion 방식에서 각 feature들을 fusion할 때 단순 합하는게 아닌 weight를 줘서 합해야한다고 제안했습니다.
Multi-scale의 feature들을 weight sum 하는 방식에도 여러가지가 나뉘어 이에 대해서도 분석을 하고 한가지를 선정했습니다.
- Unbounded fusion
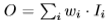
위와 같은 수식으로 정의 되며 w는 weight, I는 input feature를 의미합니다. 즉, 이 방법론은 learnable한 weight를 input feature에 곱해 합하는 방식입니다. 그리고 곱해지는 weight는 매 feature 마다 곱하는 scalar, 각 채널마다 곱하는 vector, 매 픽셀마다 곱하는 tensor로 나타내어질 수 있습니다. 그러나 이 방식은 weight의 크기에 제한을 두지 않아서 불안정한 학습을 유발할 수 있는 단점이 있습니다.
- Softmax-based fusion
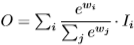
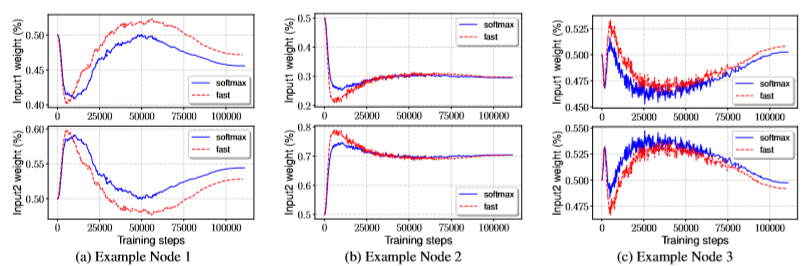
Weight를 softmax 취하여 각 feature에 적용하는 이 방식은 모든 weight를 0과 1사이로 정규화하여 사용하기에 학습이 불안정하지는 않지만 다음에 소개할 방식과 정확도(mAP)는 유사한데 inference 속도가 느려 해당 모델에는 사용하지 않습니다.
- Fast normalized fusion
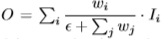
이 방식은 softmax-based 방식과 달리 weight의 평균을 낸 값을 각 feature에 곱해줍니다. 평균을 내기 이전에 모든 weight를 항상 양수로 만들기 위해 Relu를 통과 시키고 모든 weight가 Relu를 통과한 후 0이 되어 버리면 분모가 0이 되어 학습이 불안정해질 수 있는 점 때문에 0.0001인 epsilon값을 넣어주어 이를 방지했습니다. Softmax-based 방식과 정확도(mAP)는 유사하지만 exponential 연산이 없기에 GPU로 돌렸을 때 30%정도 더 빠른 것을 실험을 통해 알아내고 본 논문에서는 이 방식으로 weight fusion을 진행했습니다.
1.2 Cross-Scale Connections
Multi-scale의 feature fusion에도 어떤 feature들을 서로 fusion할 지에 대한 여러 방법론이 있었습니다.
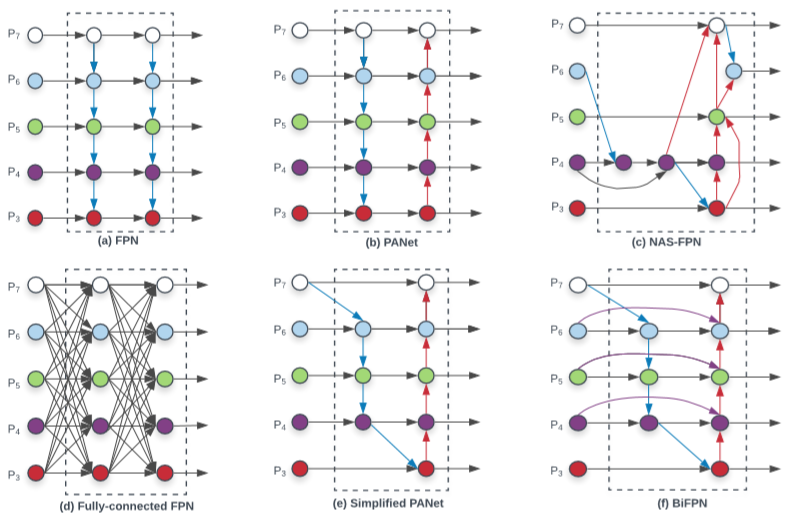
FPN에서는 low-resolution feature를 high-resolution feature에 더해주는 top-down 방식을 사용했고 이는 한 쪽 방향으로만 feature flow가 제한되었습니다. PANet에서는 이를 해결하기 위해 반대 방향인 bottom-up 방향도 추가하여 cross-scale 한 network를 설계하였습니다. 그리고 NAS-FPN에서는 어떤 feature들을 fusion하는 것인지 최적인지 설계하는 network를 구성하였으나 이는 수천 개가 넘는 GPU를 필요로 하기에 수정하기 쉽지 않은 단점이 있었습니다.
본 저자는 network efficiency를 위해 다음과 같은 세가지 조건으로 network를 설계했습니다.
- Feature fusion 없이 input feature가 하나인 노드 삭제
- 같은 level의 input과 output이 되는 노드는 fusion
- Fig 2.(f)를 여러 번 반복 (Fig 3 참고)
위 조건으로 Fig 2.(f)와 같은 network를 구성하게 되었고 각 노드(feature)들은 아래와 같은 수식으로도 나타낼 수 있습니다. (Level 6의 예시)
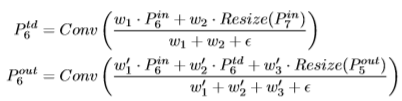
P_{6}^{td} 는 level 6의 중간 노드를 의미하며 P_{6}^{in} 은 level 6의 input 노드, P_{6}^{out} 은 output 노드를 의미합니다.
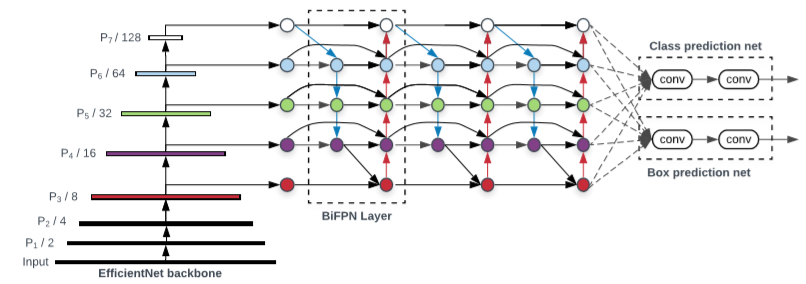
이러한 BiFPN과 EfficientNet의 backbone 모델로 Fig 3과 같은 EfficientDet을 설계하였습니다. BiFPN의 각 노드의 input은 P_{i} 일 때, 처음 영상에 비해 \frac{1}{ 2^{i} } 의 크기를 갖게되며 일정 횟수 반복 후 classification과 localization을 하게 됩니다.
2. Model scaling (Compound scaling)
기존에는 network에 input resolution이 큰 영상을 넣거나 FPN layer 여러 번 반복하여 크게 쌓은 ResNeXt나 AmoebaNet이 있었는데 본 저자는 이 network들의 scaling dimension이 제한되어 있어 비효율적이라 여기고 EfficientNet과 유사한 새로운 compound scaling 방식을 제안했습니다. 다만, Image classification을 진행한 EfficientNet과 달리, object detection인 EfficientDet은 고려해야 scaling dimension이 많아서 grid search 방식을 이용하는 대신 heuristic 방식을 차용했습니다.
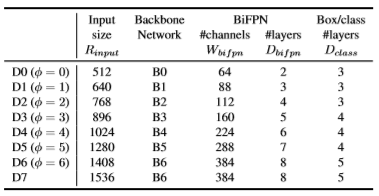
2.1 Backbone network
ImageNet으로 pretrain된 EfficientNet의 B0부터 B6까지 width/depth scaling coefficients를 그대로 사용했습니다.
2.2 BiFPN network
BiFPN의 width는 EfficientNet의 scaling coefficients처럼 exponetial하게 증가시켰으나 depth는 정수를 더해주며 증가시켰습니다. 여기서 \phi 는 EfficientNet의 버전입니다.
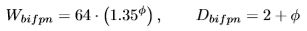
2.3 Box/class prediction network
Box/class prediction network의 width는 BiFPN과 항상 똑같게 했으며 depth는 아래 수식과 같이 선형적으로 증가시켰습니다.
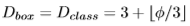
2.4 Input image resolution
BiFPN에서 feature level이 3-7까지 존재하고 최대 2^{7} 까지 down-sampling을 하기에 다음과 같은 수식으로 resolution을 정의했습니다.
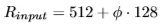
추가적으로 EfficientDet-D7일 때는 Backbone으로 \phi=7 로 사용하게 되면 메모리가 너무 커져서 batch size나 다른 실험 세팅을 바꿔야 함으로 input image resolution만 증가시켰습니다.
Result
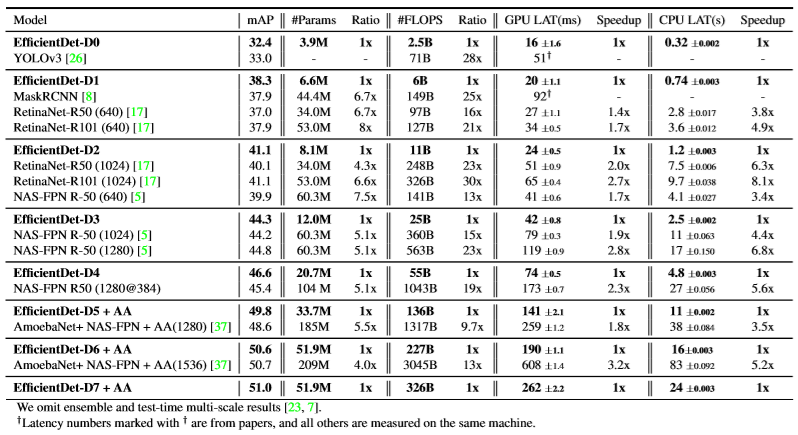
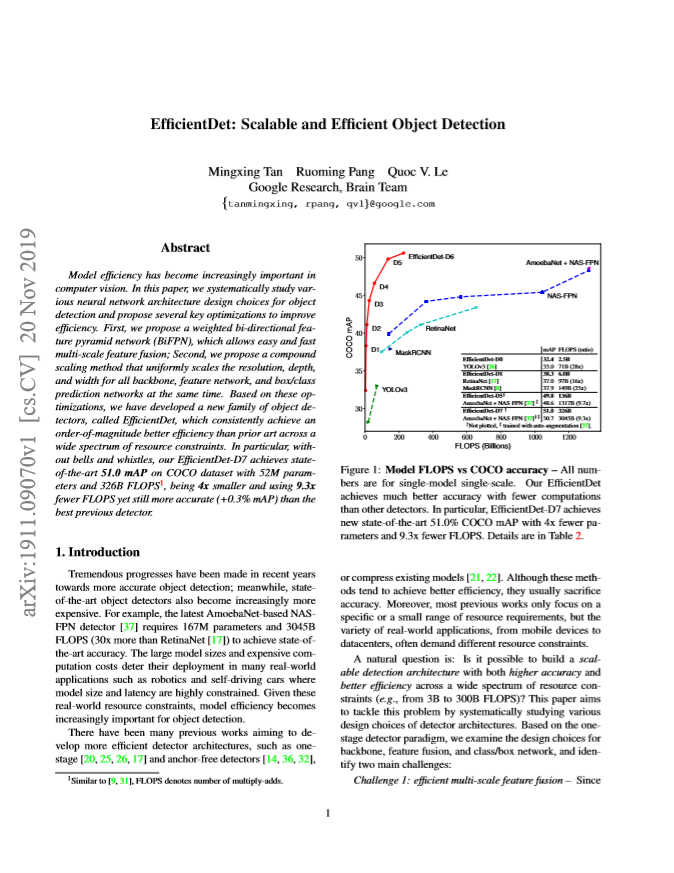
이 논문은 COCO 2017 detection dataset에서 가장 높은 mAP로 2020-04-03 현재까지도 state-of-the-art를 찍고 있습니다.
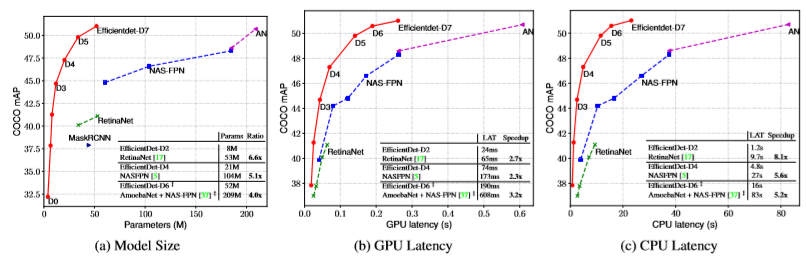
그리고 다른 network에 비해 4~6.6배 작고, GPU에서 2.3~3.2배 빠르며, CPU에서 5.2~8.1배 빠른 것을 확인할 수 있습니다.