Abstract
- CNN base detector들에게 backbone network는 feature extraction의 역할로써 성능 향상 여부에 매우 중요한 역할을 한다.
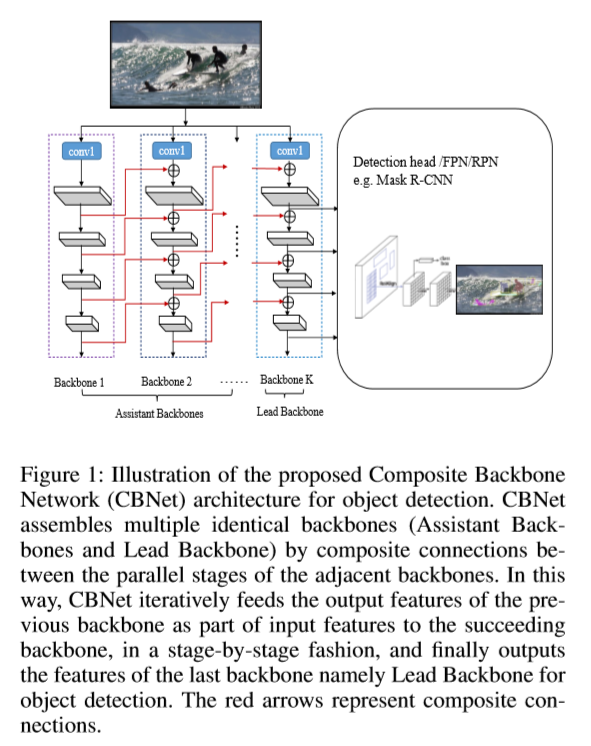
- backbone의 성능을 올리는 방법으로 인접한 동일 backbone을 composite connection하는 전략을 이용한다. -> CBNet : Composite Backbone Network
- 반복적으로 이전(k-1 th)의 backbone의 output features을 다음(k th) backbone(같은 층 input)에 넘겨준다.
- 마지막 backbone(Lead Backbone)을 Object Detection에 사용한다.
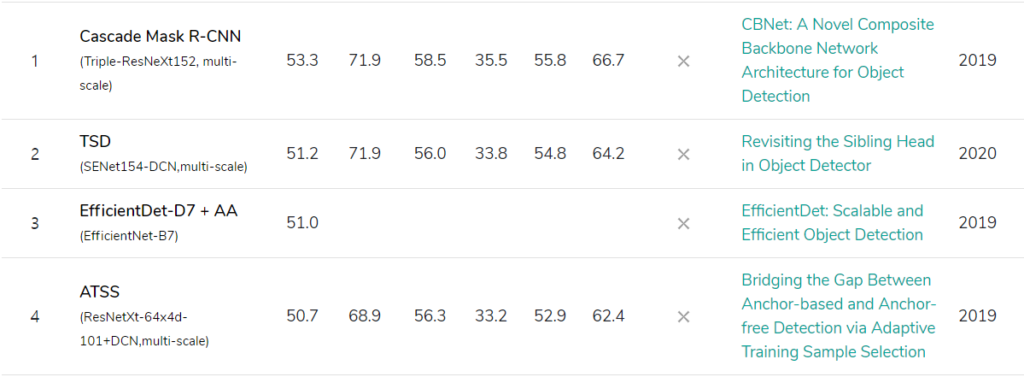
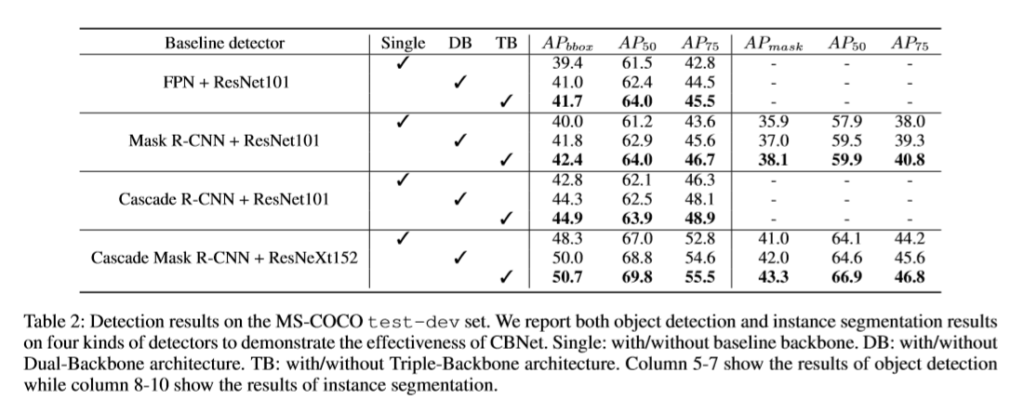
- 제안하는 backbone들을 sota detectors(FPN, Mask R-CNN, Cascade Mask R-CNN)에 적용 시, 1.5~3.0 percent의 성능 향상을 보여주었다.
- Cascade Mask R-CNN에 제안하는 backbone을 적용함으로써, COCO dataset_test_dev(mAP of 53.3)에서 state-of-the-art를 달성하였다.
- https://github.com/PKUbahuangliuhe/CBNet
Proposed method
- Architecture of CBNet
- k개의 동일한 backbone으로 구성된다. (k >= 2)
- k=2, Dual-Backbone(DB)
- k=3, Triple-Backbone(TB)
- Lead backbone B_{L} , Assistant backbone B_{1...k-1}
- 각각의 backbone은 L stage로 구성 ( L = {1, 2… l-1, l}, 일반적으로 L = 5)
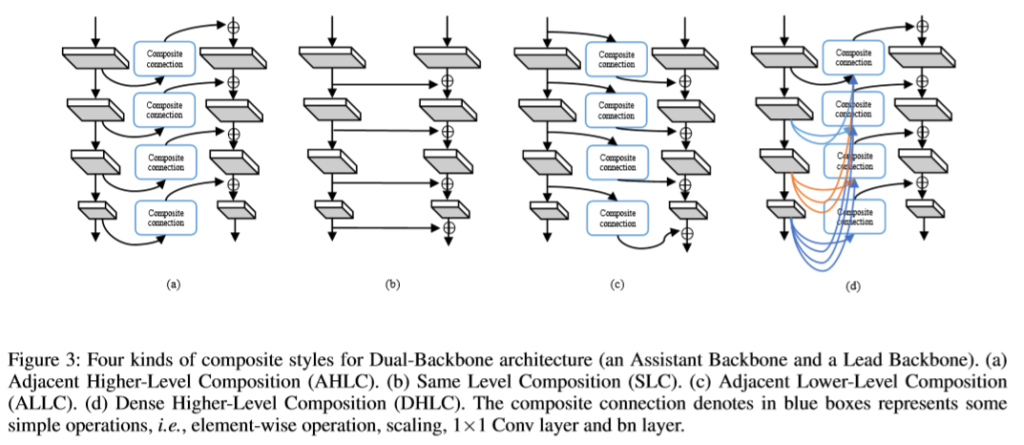
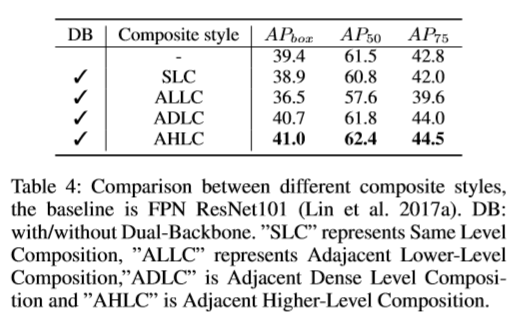
- Adjacent Higher-Level Composition(AHLC) – Main
- x_{k}^{l} = F _{k}^{l} \left( x_{k}^{l-1} + g \left( x _{k-1}^{l} \right) \right) , l >= 2
- x_{k}^{l} , k th backbone, l th stage feature
- F_{x}^{l} non-linear transformation
- g\left(\right) compsite connection, 1\times 1 conv, batch-normalization
- g\left(\right) compsite connection, 1\times 1 conv, batch-normalization
- 수식에 대해 설명하자면, k-1번째 backbone에서 같은 stage에 존재하는 feature(output)를 k 번째 backbone의 같은 stage에 존재하는 feature(input)에 전달함
- k개의 동일한 backbone으로 구성된다. (k >= 2)
- we do not need to pre-train CBNet for training a detector integrated with it. For instead, we only need to initialize each assembled backbone of CBNet with the pre-trained model of the single backbone : CBNet은 pre-train이 필요하지 않다. pre-trained backbone 모델 하나로 CBNet을 구성하면 된다.
- Other possible composite styles (+ 추가로 이런 구조도 가능하다. 건너뛰어도 무방)
- Same Level Composition (SLC)
- x_{k}^{l} = F _{k}^{l}\left( x_{k}^{l-1} + g\left(x _{k-1}^{l-1} \right) \right), l >= 2
- 이전 backbone 의 input 값을 다음 backbone의 input에 전달
- Adjacent Lower-Level Composition (ALLC)
- x_{k}^{l} = F _{k}^{l}\left( x_{k}^{l-1} + g\left(x _{k-1}^{l+1} \right) \right), l >= 2
- Inverse Level Composite (ILC)
- x_{k}^{l} = F _{k}^{l}\left( x_{k}^{l-1} + g\left(x _{k-1}^{l} \right) \right), l >= 2
- Dense Higher-Level Composition (DHLC)
- x_{k}^{l} = F _{k}^{l}\left( x_{k}^{l-1} + \sum_{i=1}^L g\left(x _{k-1}^{l} \right) \right), l >= 2
- 위의 방식을 이용하여 값을 받은 B_{K} Lead backbone을 Detector에 적용
- Same Level Composition (SLC)
Conclusion
- 이전 backbone의 output이 composite connection을 통해 병렬하게 위치한 다음 backbone에 흘러들어간다.
- 마지막 backbone의 feature map(Lead backbone)을 object detection에 사용한다.
- 실험 결과가 성능 향상 보여줌
- 특히 Mask R-CNN, Cascade R-CNN, Cascade Mask R-CNN등 instance segmentation에서 아주 좋은 효과를 보여주였다.
- 결론 Cascade Mask R-CNN에 제안하는 backbone(base on ResNeXt152)을 사용하여 COCO dataset SOTA를 달성하였다.
- ++ SOTA model에서는 Adjacent Higher-Level Composition(AHLC)를 이용했다고 합니다.
방법이 간단하고 범용성을 가지고 있어 활용도가 커 보인다. 거기다가 현재 detection에서 sota를 달성한 방법이기도 하다. 추후 다른 연구에서 backbone을 사용할 일이 생기면 해당 논문의 방법을 사용하는 것을 고려해볼 필요성이 있어 보인다.
@김태주, 깃허브 링크 죽어있는데요?
수정했습니다